擴充到大型資料集#
pandas 提供用於記憶體分析的資料結構,這使得使用 pandas 分析大於記憶體資料集的資料集變得有些棘手。即使是佔用大量記憶體的資料集也會變得難以處理,因為某些 pandas 作業需要建立中間副本。
本文提供了一些建議,以將您的分析擴充到更大的資料集。這是 提升效能 的補充,其重點在於加速適合記憶體的資料集分析。
載入較少資料#
假設我們的原始資料集在磁碟上有很多欄位。
In [1]: import pandas as pd
In [2]: import numpy as np
In [3]: def make_timeseries(start="2000-01-01", end="2000-12-31", freq="1D", seed=None):
...: index = pd.date_range(start=start, end=end, freq=freq, name="timestamp")
...: n = len(index)
...: state = np.random.RandomState(seed)
...: columns = {
...: "name": state.choice(["Alice", "Bob", "Charlie"], size=n),
...: "id": state.poisson(1000, size=n),
...: "x": state.rand(n) * 2 - 1,
...: "y": state.rand(n) * 2 - 1,
...: }
...: df = pd.DataFrame(columns, index=index, columns=sorted(columns))
...: if df.index[-1] == end:
...: df = df.iloc[:-1]
...: return df
...:
In [4]: timeseries = [
...: make_timeseries(freq="1min", seed=i).rename(columns=lambda x: f"{x}_{i}")
...: for i in range(10)
...: ]
...:
In [5]: ts_wide = pd.concat(timeseries, axis=1)
In [6]: ts_wide.head()
Out[6]:
id_0 name_0 x_0 ... name_9 x_9 y_9
timestamp ...
2000-01-01 00:00:00 977 Alice -0.821225 ... Charlie -0.957208 -0.757508
2000-01-01 00:01:00 1018 Bob -0.219182 ... Alice -0.414445 -0.100298
2000-01-01 00:02:00 927 Alice 0.660908 ... Charlie -0.325838 0.581859
2000-01-01 00:03:00 997 Bob -0.852458 ... Bob 0.992033 -0.686692
2000-01-01 00:04:00 965 Bob 0.717283 ... Charlie -0.924556 -0.184161
[5 rows x 40 columns]
In [7]: ts_wide.to_parquet("timeseries_wide.parquet")
要載入我們想要的欄位,我們有兩個選項。選項 1 載入所有資料,然後過濾成我們需要的資料。
In [8]: columns = ["id_0", "name_0", "x_0", "y_0"]
In [9]: pd.read_parquet("timeseries_wide.parquet")[columns]
Out[9]:
id_0 name_0 x_0 y_0
timestamp
2000-01-01 00:00:00 977 Alice -0.821225 0.906222
2000-01-01 00:01:00 1018 Bob -0.219182 0.350855
2000-01-01 00:02:00 927 Alice 0.660908 -0.798511
2000-01-01 00:03:00 997 Bob -0.852458 0.735260
2000-01-01 00:04:00 965 Bob 0.717283 0.393391
... ... ... ... ...
2000-12-30 23:56:00 1037 Bob -0.814321 0.612836
2000-12-30 23:57:00 980 Bob 0.232195 -0.618828
2000-12-30 23:58:00 965 Alice -0.231131 0.026310
2000-12-30 23:59:00 984 Alice 0.942819 0.853128
2000-12-31 00:00:00 1003 Alice 0.201125 -0.136655
[525601 rows x 4 columns]
選項 2 只載入我們要求的欄位。
In [10]: pd.read_parquet("timeseries_wide.parquet", columns=columns)
Out[10]:
id_0 name_0 x_0 y_0
timestamp
2000-01-01 00:00:00 977 Alice -0.821225 0.906222
2000-01-01 00:01:00 1018 Bob -0.219182 0.350855
2000-01-01 00:02:00 927 Alice 0.660908 -0.798511
2000-01-01 00:03:00 997 Bob -0.852458 0.735260
2000-01-01 00:04:00 965 Bob 0.717283 0.393391
... ... ... ... ...
2000-12-30 23:56:00 1037 Bob -0.814321 0.612836
2000-12-30 23:57:00 980 Bob 0.232195 -0.618828
2000-12-30 23:58:00 965 Alice -0.231131 0.026310
2000-12-30 23:59:00 984 Alice 0.942819 0.853128
2000-12-31 00:00:00 1003 Alice 0.201125 -0.136655
[525601 rows x 4 columns]
如果我們要測量這兩個呼叫的記憶體使用量,我們會看到指定 columns 在這種情況下使用約 1/10 的記憶體。
使用 pandas.read_csv(),您可以指定 usecols 來限制讀取到記憶體中的欄位。並非所有可以由 pandas 讀取的檔案格式都提供讀取子集欄位的選項。
使用有效率的資料類型#
預設的 pandas 資料類型並非最有效率的記憶體。這對於具有相對較少唯一值的文字資料欄位(通常稱為「低基數」資料)尤其如此。透過使用更有效率的資料類型,您可以將更大的資料集儲存在記憶體中。
In [11]: ts = make_timeseries(freq="30s", seed=0)
In [12]: ts.to_parquet("timeseries.parquet")
In [13]: ts = pd.read_parquet("timeseries.parquet")
In [14]: ts
Out[14]:
id name x y
timestamp
2000-01-01 00:00:00 1041 Alice 0.889987 0.281011
2000-01-01 00:00:30 988 Bob -0.455299 0.488153
2000-01-01 00:01:00 1018 Alice 0.096061 0.580473
2000-01-01 00:01:30 992 Bob 0.142482 0.041665
2000-01-01 00:02:00 960 Bob -0.036235 0.802159
... ... ... ... ...
2000-12-30 23:58:00 1022 Alice 0.266191 0.875579
2000-12-30 23:58:30 974 Alice -0.009826 0.413686
2000-12-30 23:59:00 1028 Charlie 0.307108 -0.656789
2000-12-30 23:59:30 1002 Alice 0.202602 0.541335
2000-12-31 00:00:00 987 Alice 0.200832 0.615972
[1051201 rows x 4 columns]
現在,讓我們檢查資料類型和記憶體使用量,以了解我們應該將注意力集中在哪裡。
In [15]: ts.dtypes
Out[15]:
id int64
name object
x float64
y float64
dtype: object
In [16]: ts.memory_usage(deep=True) # memory usage in bytes
Out[16]:
Index 8409608
id 8409608
name 65176434
x 8409608
y 8409608
dtype: int64
name 欄位佔用的記憶體比其他欄位都多。它只有少數幾個獨特值,因此很適合轉換成 pandas.Categorical。使用 pandas.Categorical,我們會儲存每個獨特名稱一次,並使用省空間的整數來得知每列中使用的特定名稱。
In [17]: ts2 = ts.copy()
In [18]: ts2["name"] = ts2["name"].astype("category")
In [19]: ts2.memory_usage(deep=True)
Out[19]:
Index 8409608
id 8409608
name 1051495
x 8409608
y 8409608
dtype: int64
我們可以更進一步,使用 pandas.to_numeric() 將數字欄位向下轉換成最小的型別。
In [20]: ts2["id"] = pd.to_numeric(ts2["id"], downcast="unsigned")
In [21]: ts2[["x", "y"]] = ts2[["x", "y"]].apply(pd.to_numeric, downcast="float")
In [22]: ts2.dtypes
Out[22]:
id uint16
name category
x float32
y float32
dtype: object
In [23]: ts2.memory_usage(deep=True)
Out[23]:
Index 8409608
id 2102402
name 1051495
x 4204804
y 4204804
dtype: int64
In [24]: reduction = ts2.memory_usage(deep=True).sum() / ts.memory_usage(deep=True).sum()
In [25]: print(f"{reduction:0.2f}")
0.20
總而言之,我們已將此資料集在記憶體中的空間縮小到原本大小的 1/5。
請參閱 類別資料 以進一步了解 pandas.Categorical,並參閱 資料型態 以概觀所有 pandas 的資料型態。
使用分塊#
某些工作負載可透過將大型問題分割成一堆小問題來達成分塊。例如,將個別 CSV 檔案轉換成 Parquet 檔案,並對目錄中的每個檔案重複此動作。只要每個區塊都符合記憶體大小,您就可以使用遠大於記憶體的資料集。
注意
當您執行的作業不需要區塊之間的協調,或僅需極少的協調時,分塊會很有效。對於較複雜的工作流程,您最好 使用其他函式庫。
假設我們有一個更大的「邏輯資料集」在磁碟上,是一個 parquet 檔案的目錄。目錄中的每個檔案代表整個資料集的不同年份。
In [26]: import pathlib
In [27]: N = 12
In [28]: starts = [f"20{i:>02d}-01-01" for i in range(N)]
In [29]: ends = [f"20{i:>02d}-12-13" for i in range(N)]
In [30]: pathlib.Path("data/timeseries").mkdir(exist_ok=True)
In [31]: for i, (start, end) in enumerate(zip(starts, ends)):
....: ts = make_timeseries(start=start, end=end, freq="1min", seed=i)
....: ts.to_parquet(f"data/timeseries/ts-{i:0>2d}.parquet")
....:
data
└── timeseries
├── ts-00.parquet
├── ts-01.parquet
├── ts-02.parquet
├── ts-03.parquet
├── ts-04.parquet
├── ts-05.parquet
├── ts-06.parquet
├── ts-07.parquet
├── ts-08.parquet
├── ts-09.parquet
├── ts-10.parquet
└── ts-11.parquet
現在我們將實作一個非核心 pandas.Series.value_counts()。此工作流程的記憶體使用量高峰是單一最大區塊,加上一個儲存到目前為止的唯一值計數的小系列。只要每個個別檔案都符合記憶體,這將適用於任意大小的資料集。
In [32]: %%time
....: files = pathlib.Path("data/timeseries/").glob("ts*.parquet")
....: counts = pd.Series(dtype=int)
....: for path in files:
....: df = pd.read_parquet(path)
....: counts = counts.add(df["name"].value_counts(), fill_value=0)
....: counts.astype(int)
....:
CPU times: user 744 ms, sys: 28.7 ms, total: 773 ms
Wall time: 551 ms
Out[32]:
name
Alice 1994645
Bob 1993692
Charlie 1994875
dtype: int64
有些讀取器,例如 pandas.read_csv(),提供參數來控制讀取單一檔案時的 chunksize。
手動分塊是對不需要太複雜操作的工作流程而言不錯的選項。有些操作,例如 pandas.DataFrame.groupby(),以分塊方式執行難度高得多。在這些情況下,你最好切換到不同的函式庫,為你實作這些非核心演算法。
使用 Dask#
pandas 只是提供 DataFrame API 的一個函式庫。由於其受歡迎程度,pandas 的 API 已成為其他函式庫實作的標準。pandas 文件在 生態系統頁面 中維護一個實作 DataFrame API 的函式庫清單。
例如,平行運算函式庫 Dask 有 dask.dataframe,一個類似 pandas 的 API,用於平行處理比記憶體大的資料集。Dask 可以使用單一機器上的多個執行緒或程序,或使用機器叢集平行處理資料。
我們將匯入 dask.dataframe,並注意到 API 感覺類似於 pandas。我們可以使用 Dask 的 read_parquet 函式,但提供要讀取的檔案的 glob 字串。
In [33]: import dask.dataframe as dd
In [34]: ddf = dd.read_parquet("data/timeseries/ts*.parquet", engine="pyarrow")
In [35]: ddf
Out[35]:
Dask DataFrame Structure:
id name x y
npartitions=12
int64 string float64 float64
... ... ... ...
... ... ... ... ...
... ... ... ...
... ... ... ...
Dask Name: read-parquet, 1 graph layer
檢查 ddf 物件,我們會看到一些事情
有一些熟悉的屬性,例如
.columns和.dtypes有一些熟悉的函式,例如
.groupby、.sum等。有一些新的屬性,例如
.npartitions和.divisions
分割和區段是 Dask 如何並行化運算。一個 Dask DataFrame 由許多 pandas pandas.DataFrame 組成。對 Dask DataFrame 進行單一函式呼叫最終會產生許多 pandas 函式呼叫,而 Dask 知道如何協調所有內容以取得結果。
In [36]: ddf.columns
Out[36]: Index(['id', 'name', 'x', 'y'], dtype='object')
In [37]: ddf.dtypes
Out[37]:
id int64
name string[pyarrow]
x float64
y float64
dtype: object
In [38]: ddf.npartitions
Out[38]: 12
一個主要的差異:dask.dataframe API 是延遲的。如果您查看上方的 repr,您會注意到值並未實際列印出來;只有欄位名稱和 dtypes。這是因為 Dask 尚未實際讀取資料。執行作業會建立一個任務圖形,而不是立即執行。
In [39]: ddf
Out[39]:
Dask DataFrame Structure:
id name x y
npartitions=12
int64 string float64 float64
... ... ... ...
... ... ... ... ...
... ... ... ...
... ... ... ...
Dask Name: read-parquet, 1 graph layer
In [40]: ddf["name"]
Out[40]:
Dask Series Structure:
npartitions=12
string
...
...
...
...
Name: name, dtype: string
Dask Name: getitem, 2 graph layers
In [41]: ddf["name"].value_counts()
Out[41]:
Dask Series Structure:
npartitions=1
int64[pyarrow]
...
Name: count, dtype: int64[pyarrow]
Dask Name: value-counts-agg, 4 graph layers
這些呼叫都是即時的,因為結果尚未計算。我們只是建立一個計算清單,以便在有人需要結果時執行。Dask 知道 pandas.Series.value_counts 的回傳類型是具有特定 dtype 和特定名稱的 pandas pandas.Series。因此,Dask 版本會回傳具有相同 dtype 和相同名稱的 Dask Series。
若要取得實際結果,您可以呼叫 .compute()。
In [42]: %time ddf["name"].value_counts().compute()
CPU times: user 538 ms, sys: 45.8 ms, total: 584 ms
Wall time: 165 ms
Out[42]:
name
Charlie 1994875
Alice 1994645
Bob 1993692
Name: count, dtype: int64[pyarrow]
在那個時間點,您會取得與使用 pandas 相同的東西,在本例中為具體的 pandas pandas.Series,其中包含每個 name 的計數。
呼叫 .compute 會導致執行完整的任務圖形。這包括讀取資料、選取欄位,以及執行 value_counts。執行會在可能的情況下並行進行,而 Dask 會嘗試保持整體記憶體使用量較小。只要每個分割區(常規 pandas pandas.DataFrame)符合記憶體,您就可以使用遠大於記憶體的資料集。
預設情況下,dask.dataframe 作業使用執行緒池來平行進行作業。我們也可以連線到叢集,在多部機器上分配工作。在這個案例中,我們將連線到由這部機器上的多個程序組成的本機「叢集」。
>>> from dask.distributed import Client, LocalCluster
>>> cluster = LocalCluster()
>>> client = Client(cluster)
>>> client
<Client: 'tcp://127.0.0.1:53349' processes=4 threads=8, memory=17.18 GB>
一旦建立這個client,Dask 的所有運算都會在叢集上進行(在本例中,叢集只是程序)。
Dask 實作了 pandas API 中最常用的部分。例如,我們可以執行熟悉的 groupby 聚合。
In [43]: %time ddf.groupby("name")[["x", "y"]].mean().compute().head()
CPU times: user 1.04 s, sys: 66.7 ms, total: 1.1 s
Wall time: 319 ms
Out[43]:
x y
name
Alice -0.000224 -0.000194
Bob -0.000746 0.000349
Charlie 0.000604 0.000250
分組和聚合會在核心外部平行進行。
當 Dask 知道資料集的divisions時,可以進行某些最佳化。當讀取由 dask 編寫的 parquet 資料集時,系統會自動知道 divisions。在本例中,由於我們手動建立了 parquet 檔案,因此需要手動提供 divisions。
In [44]: N = 12
In [45]: starts = [f"20{i:>02d}-01-01" for i in range(N)]
In [46]: ends = [f"20{i:>02d}-12-13" for i in range(N)]
In [47]: divisions = tuple(pd.to_datetime(starts)) + (pd.Timestamp(ends[-1]),)
In [48]: ddf.divisions = divisions
In [49]: ddf
Out[49]:
Dask DataFrame Structure:
id name x y
npartitions=12
2000-01-01 int64 string float64 float64
2001-01-01 ... ... ... ...
... ... ... ... ...
2011-01-01 ... ... ... ...
2011-12-13 ... ... ... ...
Dask Name: read-parquet, 1 graph layer
現在,我們可以執行諸如使用.loc進行快速隨機存取等操作。
In [50]: ddf.loc["2002-01-01 12:01":"2002-01-01 12:05"].compute()
Out[50]:
id name x y
timestamp
2002-01-01 12:01:00 971 Bob -0.659481 0.556184
2002-01-01 12:02:00 1015 Charlie 0.120131 -0.609522
2002-01-01 12:03:00 991 Bob -0.357816 0.811362
2002-01-01 12:04:00 984 Alice -0.608760 0.034187
2002-01-01 12:05:00 998 Charlie 0.551662 -0.461972
Dask 知道只在第 3 個分割區中尋找 2002 年的值。它不需要查看任何其他資料。
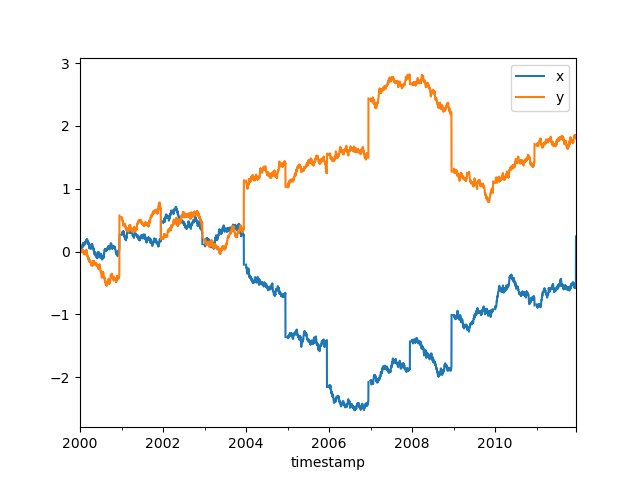
許多工作流程涉及大量資料,並以某種方式處理這些資料,將大小縮小到可以放入記憶體中。在本例中,我們將重新取樣為每日頻率並取平均值。一旦我們取了平均值,我們就知道結果可以放入記憶體中,因此我們可以安全地呼叫compute而不會用完記憶體。在那個時間點,它只是一個常規的 pandas 物件。
In [51]: ddf[["x", "y"]].resample("1D").mean().cumsum().compute().plot()
Out[51]: <Axes: xlabel='timestamp'>
這些 Dask 範例都是在單一機器上使用多個程序完成的。Dask 可以部署在叢集上,以擴充到更大的資料集。
您可以在https://examples.dask.org看到更多 dask 範例。