索引和選取資料#
pandas 物件中的軸標籤資訊有許多用途
使用已知指標識別資料(即提供元資料),這對於分析、視覺化和互動式主控台顯示很重要。
啟用自動和明確的資料對齊。
允許直覺地取得和設定資料集的子集。
在本節中,我們將專注於最後一點:即如何切片、切塊,以及一般取得和設定 pandas 物件的子集。主要焦點將放在 Series 和 DataFrame 上,因為它們在這方面獲得了更多開發關注。
注意
Python 和 NumPy 編製運算子 [] 和屬性運算子 . 提供快速且容易存取各種使用案例中的 pandas 資料結構。這使得互動工作直覺,因為如果您已經知道如何處理 Python 字典和 NumPy 陣列,則幾乎沒有什麼新東西需要學習。但是,由於要存取的資料類型事先並不知道,因此直接使用標準運算子會有一些最佳化限制。對於製作程式碼,我們建議您利用本章中公開的最佳化 pandas 資料存取方法。
警告
設定作業是否傳回複製或參考,可能取決於上下文。這有時稱為 連鎖 指派,應避免使用。請參閱 傳回檢視與複製。
請參閱 多重索引/進階編製,以取得 多重索引 和更進階的編製文件。
請參閱 食譜,以取得一些進階策略。
編製的不同選擇#
物件選擇已經有許多使用者要求的增補,以支援更明確的基於位置的編製。pandas 現在支援三種類型的多軸編製。
.loc主要基於標籤,但也可以用於布林陣列。.loc在找不到項目時會引發KeyError。允許的輸入為請參閱 依標籤選取 以取得更多資訊。
.iloc主要基於整數位置(從0到軸的length-1),但也可以與布林陣列一起使用。如果請求的索引器超出範圍,.iloc會引發IndexError,但允許超出範圍索引的 切片 索引器除外。(這符合 Python/NumPy 切片 語意)。允許的輸入為整數,例如
5。整數清單或陣列
[4, 3, 0]。包含整數的切片物件
1:7。布林陣列(任何
NA值都將被視為False)。具有單個參數(呼叫的 Series 或 DataFrame)的
callable函數,並傳回索引的有效輸出(上述之一)。列(和欄)索引的元組,其元素是上述輸入之一。
.loc、.iloc,以及[]索引可以接受callable作為索引器。請參閱 依據可呼叫選取 以取得更多資訊。注意
在套用可呼叫之前,會將結構化元組鍵分解成列(和欄)索引,因此您無法從可呼叫傳回元組來索引列和欄。
從具有多軸選擇的物件取得值時,請使用下列符號(使用 .loc 作為範例,但下列內容也適用於 .iloc)。任何軸存取器都可以是空片段 :。未包含在規格中的軸假設為 :,例如 p.loc['a'] 等同於 p.loc['a', :]。
物件類型 |
索引器 |
|---|---|
序列 |
|
資料框 |
|
基礎知識#
如在 上一節介紹資料結構時所述,使用 [](對於熟悉在 Python 中實作類別行為的人來說,也稱為 __getitem__)進行索引的主要功能是選取較低維度的片段。下表顯示使用 [] 對 pandas 物件進行索引時的傳回類型值
物件類型 |
選擇 |
傳回值類型 |
|---|---|---|
序列 |
|
純量值 |
資料框 |
|
對應於欄位名稱的 |
在此,我們建構一個簡單的時間序列資料集,用於說明索引功能
In [1]: dates = pd.date_range('1/1/2000', periods=8)
In [2]: df = pd.DataFrame(np.random.randn(8, 4),
...: index=dates, columns=['A', 'B', 'C', 'D'])
...:
In [3]: df
Out[3]:
A B C D
2000-01-01 0.469112 -0.282863 -1.509059 -1.135632
2000-01-02 1.212112 -0.173215 0.119209 -1.044236
2000-01-03 -0.861849 -2.104569 -0.494929 1.071804
2000-01-04 0.721555 -0.706771 -1.039575 0.271860
2000-01-05 -0.424972 0.567020 0.276232 -1.087401
2000-01-06 -0.673690 0.113648 -1.478427 0.524988
2000-01-07 0.404705 0.577046 -1.715002 -1.039268
2000-01-08 -0.370647 -1.157892 -1.344312 0.844885
注意
除非特別說明,否則沒有任何索引功能是特定於時間序列的。
因此,根據上述內容,我們有最基本的索引使用 []
In [4]: s = df['A']
In [5]: s[dates[5]]
Out[5]: -0.6736897080883706
您可以傳遞一串欄位給 [] 來依序選取欄位。如果 DataFrame 中不包含欄位,將會引發例外。也可以用這種方式設定多個欄位
In [6]: df
Out[6]:
A B C D
2000-01-01 0.469112 -0.282863 -1.509059 -1.135632
2000-01-02 1.212112 -0.173215 0.119209 -1.044236
2000-01-03 -0.861849 -2.104569 -0.494929 1.071804
2000-01-04 0.721555 -0.706771 -1.039575 0.271860
2000-01-05 -0.424972 0.567020 0.276232 -1.087401
2000-01-06 -0.673690 0.113648 -1.478427 0.524988
2000-01-07 0.404705 0.577046 -1.715002 -1.039268
2000-01-08 -0.370647 -1.157892 -1.344312 0.844885
In [7]: df[['B', 'A']] = df[['A', 'B']]
In [8]: df
Out[8]:
A B C D
2000-01-01 -0.282863 0.469112 -1.509059 -1.135632
2000-01-02 -0.173215 1.212112 0.119209 -1.044236
2000-01-03 -2.104569 -0.861849 -0.494929 1.071804
2000-01-04 -0.706771 0.721555 -1.039575 0.271860
2000-01-05 0.567020 -0.424972 0.276232 -1.087401
2000-01-06 0.113648 -0.673690 -1.478427 0.524988
2000-01-07 0.577046 0.404705 -1.715002 -1.039268
2000-01-08 -1.157892 -0.370647 -1.344312 0.844885
您可能會發現這對於將轉換(就地)套用至欄位子集很有用。
警告
pandas 在從 .loc 設定 Series 和 DataFrame 時會比對所有軸。
這不會修改 df,因為欄位比對在值指派之前。
In [9]: df[['A', 'B']]
Out[9]:
A B
2000-01-01 -0.282863 0.469112
2000-01-02 -0.173215 1.212112
2000-01-03 -2.104569 -0.861849
2000-01-04 -0.706771 0.721555
2000-01-05 0.567020 -0.424972
2000-01-06 0.113648 -0.673690
2000-01-07 0.577046 0.404705
2000-01-08 -1.157892 -0.370647
In [10]: df.loc[:, ['B', 'A']] = df[['A', 'B']]
In [11]: df[['A', 'B']]
Out[11]:
A B
2000-01-01 -0.282863 0.469112
2000-01-02 -0.173215 1.212112
2000-01-03 -2.104569 -0.861849
2000-01-04 -0.706771 0.721555
2000-01-05 0.567020 -0.424972
2000-01-06 0.113648 -0.673690
2000-01-07 0.577046 0.404705
2000-01-08 -1.157892 -0.370647
交換欄位值的正確方式是使用原始值
In [12]: df.loc[:, ['B', 'A']] = df[['A', 'B']].to_numpy()
In [13]: df[['A', 'B']]
Out[13]:
A B
2000-01-01 0.469112 -0.282863
2000-01-02 1.212112 -0.173215
2000-01-03 -0.861849 -2.104569
2000-01-04 0.721555 -0.706771
2000-01-05 -0.424972 0.567020
2000-01-06 -0.673690 0.113648
2000-01-07 0.404705 0.577046
2000-01-08 -0.370647 -1.157892
不過,pandas 在從 .iloc 設定 Series 和 DataFrame 時不會比對軸,因為 .iloc 是依位置運作。
這會修改 df,因為欄位比對在值指派之前未完成。
In [14]: df[['A', 'B']]
Out[14]:
A B
2000-01-01 0.469112 -0.282863
2000-01-02 1.212112 -0.173215
2000-01-03 -0.861849 -2.104569
2000-01-04 0.721555 -0.706771
2000-01-05 -0.424972 0.567020
2000-01-06 -0.673690 0.113648
2000-01-07 0.404705 0.577046
2000-01-08 -0.370647 -1.157892
In [15]: df.iloc[:, [1, 0]] = df[['A', 'B']]
In [16]: df[['A','B']]
Out[16]:
A B
2000-01-01 -0.282863 0.469112
2000-01-02 -0.173215 1.212112
2000-01-03 -2.104569 -0.861849
2000-01-04 -0.706771 0.721555
2000-01-05 0.567020 -0.424972
2000-01-06 0.113648 -0.673690
2000-01-07 0.577046 0.404705
2000-01-08 -1.157892 -0.370647
屬性存取#
您可以直接將 Series 上的索引或 DataFrame 上的欄位當作屬性存取
In [17]: sa = pd.Series([1, 2, 3], index=list('abc'))
In [18]: dfa = df.copy()
In [19]: sa.b
Out[19]: 2
In [20]: dfa.A
Out[20]:
2000-01-01 -0.282863
2000-01-02 -0.173215
2000-01-03 -2.104569
2000-01-04 -0.706771
2000-01-05 0.567020
2000-01-06 0.113648
2000-01-07 0.577046
2000-01-08 -1.157892
Freq: D, Name: A, dtype: float64
In [21]: sa.a = 5
In [22]: sa
Out[22]:
a 5
b 2
c 3
dtype: int64
In [23]: dfa.A = list(range(len(dfa.index))) # ok if A already exists
In [24]: dfa
Out[24]:
A B C D
2000-01-01 0 0.469112 -1.509059 -1.135632
2000-01-02 1 1.212112 0.119209 -1.044236
2000-01-03 2 -0.861849 -0.494929 1.071804
2000-01-04 3 0.721555 -1.039575 0.271860
2000-01-05 4 -0.424972 0.276232 -1.087401
2000-01-06 5 -0.673690 -1.478427 0.524988
2000-01-07 6 0.404705 -1.715002 -1.039268
2000-01-08 7 -0.370647 -1.344312 0.844885
In [25]: dfa['A'] = list(range(len(dfa.index))) # use this form to create a new column
In [26]: dfa
Out[26]:
A B C D
2000-01-01 0 0.469112 -1.509059 -1.135632
2000-01-02 1 1.212112 0.119209 -1.044236
2000-01-03 2 -0.861849 -0.494929 1.071804
2000-01-04 3 0.721555 -1.039575 0.271860
2000-01-05 4 -0.424972 0.276232 -1.087401
2000-01-06 5 -0.673690 -1.478427 0.524988
2000-01-07 6 0.404705 -1.715002 -1.039268
2000-01-08 7 -0.370647 -1.344312 0.844885
警告
只有索引元素為有效的 Python 識別碼時,您才能使用此存取方式,例如
s.1不被允許。請參閱 此處,以了解有效的識別碼說明。如果屬性與現有方法名稱衝突,則該屬性將不可用,例如
s.min不被允許,但s['min']則可以。類似地,如果屬性與下列清單中的任何項目衝突,則該屬性將不可用:
index、major_axis、minor_axis、items。在任何這些情況下,標準索引仍會運作,例如
s['1']、s['min']和s['index']將存取對應的元素或欄位。
如果您使用 IPython 環境,您也可以使用 Tab 補完來查看這些可存取的屬性。
您也可以將 dict 指定給 DataFrame 的列
In [27]: x = pd.DataFrame({'x': [1, 2, 3], 'y': [3, 4, 5]})
In [28]: x.iloc[1] = {'x': 9, 'y': 99}
In [29]: x
Out[29]:
x y
0 1 3
1 9 99
2 3 5
您可以使用屬性存取來修改 Series 的現有元素或 DataFrame 的欄位,但請小心;如果您嘗試使用屬性存取來建立新欄位,它會建立新屬性而不是新欄位,並會引發 UserWarning
In [30]: df_new = pd.DataFrame({'one': [1., 2., 3.]})
In [31]: df_new.two = [4, 5, 6]
In [32]: df_new
Out[32]:
one
0 1.0
1 2.0
2 3.0
切片範圍#
在任意軸線上切片範圍最健全且一致的方法說明於 依位置選取 區段,其中詳細說明 .iloc 方法。目前,我們說明使用 [] 算子切片的語意。
使用 Series 時,語法與使用 ndarray 完全相同,會傳回值的切片和對應的標籤
In [33]: s[:5]
Out[33]:
2000-01-01 0.469112
2000-01-02 1.212112
2000-01-03 -0.861849
2000-01-04 0.721555
2000-01-05 -0.424972
Freq: D, Name: A, dtype: float64
In [34]: s[::2]
Out[34]:
2000-01-01 0.469112
2000-01-03 -0.861849
2000-01-05 -0.424972
2000-01-07 0.404705
Freq: 2D, Name: A, dtype: float64
In [35]: s[::-1]
Out[35]:
2000-01-08 -0.370647
2000-01-07 0.404705
2000-01-06 -0.673690
2000-01-05 -0.424972
2000-01-04 0.721555
2000-01-03 -0.861849
2000-01-02 1.212112
2000-01-01 0.469112
Freq: -1D, Name: A, dtype: float64
請注意設定也適用
In [36]: s2 = s.copy()
In [37]: s2[:5] = 0
In [38]: s2
Out[38]:
2000-01-01 0.000000
2000-01-02 0.000000
2000-01-03 0.000000
2000-01-04 0.000000
2000-01-05 0.000000
2000-01-06 -0.673690
2000-01-07 0.404705
2000-01-08 -0.370647
Freq: D, Name: A, dtype: float64
使用 DataFrame 時,在 [] 內切片會切片列。這主要是提供便利性,因為這是一個很常見的作業。
In [39]: df[:3]
Out[39]:
A B C D
2000-01-01 -0.282863 0.469112 -1.509059 -1.135632
2000-01-02 -0.173215 1.212112 0.119209 -1.044236
2000-01-03 -2.104569 -0.861849 -0.494929 1.071804
In [40]: df[::-1]
Out[40]:
A B C D
2000-01-08 -1.157892 -0.370647 -1.344312 0.844885
2000-01-07 0.577046 0.404705 -1.715002 -1.039268
2000-01-06 0.113648 -0.673690 -1.478427 0.524988
2000-01-05 0.567020 -0.424972 0.276232 -1.087401
2000-01-04 -0.706771 0.721555 -1.039575 0.271860
2000-01-03 -2.104569 -0.861849 -0.494929 1.071804
2000-01-02 -0.173215 1.212112 0.119209 -1.044236
2000-01-01 -0.282863 0.469112 -1.509059 -1.135632
依標籤選取#
警告
設定作業是否傳回複製或參考,可能取決於上下文。這有時稱為 連鎖 指派,應避免使用。請參閱 傳回檢視與複製。
警告
當您提供與索引類型不相容(或無法轉換)的切片器時,
.loc會很嚴格。例如在DatetimeIndex中使用整數。這些會引發TypeError。In [41]: dfl = pd.DataFrame(np.random.randn(5, 4), ....: columns=list('ABCD'), ....: index=pd.date_range('20130101', periods=5)) ....: In [42]: dfl Out[42]: A B C D 2013-01-01 1.075770 -0.109050 1.643563 -1.469388 2013-01-02 0.357021 -0.674600 -1.776904 -0.968914 2013-01-03 -1.294524 0.413738 0.276662 -0.472035 2013-01-04 -0.013960 -0.362543 -0.006154 -0.923061 2013-01-05 0.895717 0.805244 -1.206412 2.565646 In [43]: dfl.loc[2:3] --------------------------------------------------------------------------- TypeError Traceback (most recent call last) Cell In[43], line 1 ----> 1 dfl.loc[2:3] File ~/work/pandas/pandas/pandas/core/indexing.py:1191, in _LocationIndexer.__getitem__(self, key) 1189 maybe_callable = com.apply_if_callable(key, self.obj) 1190 maybe_callable = self._check_deprecated_callable_usage(key, maybe_callable) -> 1191 return self._getitem_axis(maybe_callable, axis=axis) File ~/work/pandas/pandas/pandas/core/indexing.py:1411, in _LocIndexer._getitem_axis(self, key, axis) 1409 if isinstance(key, slice): 1410 self._validate_key(key, axis) -> 1411 return self._get_slice_axis(key, axis=axis) 1412 elif com.is_bool_indexer(key): 1413 return self._getbool_axis(key, axis=axis) File ~/work/pandas/pandas/pandas/core/indexing.py:1443, in _LocIndexer._get_slice_axis(self, slice_obj, axis) 1440 return obj.copy(deep=False) 1442 labels = obj._get_axis(axis) -> 1443 indexer = labels.slice_indexer(slice_obj.start, slice_obj.stop, slice_obj.step) 1445 if isinstance(indexer, slice): 1446 return self.obj._slice(indexer, axis=axis) File ~/work/pandas/pandas/pandas/core/indexes/datetimes.py:682, in DatetimeIndex.slice_indexer(self, start, end, step) 674 # GH#33146 if start and end are combinations of str and None and Index is not 675 # monotonic, we can not use Index.slice_indexer because it does not honor the 676 # actual elements, is only searching for start and end 677 if ( 678 check_str_or_none(start) 679 or check_str_or_none(end) 680 or self.is_monotonic_increasing 681 ): --> 682 return Index.slice_indexer(self, start, end, step) 684 mask = np.array(True) 685 in_index = True File ~/work/pandas/pandas/pandas/core/indexes/base.py:6662, in Index.slice_indexer(self, start, end, step) 6618 def slice_indexer( 6619 self, 6620 start: Hashable | None = None, 6621 end: Hashable | None = None, 6622 step: int | None = None, 6623 ) -> slice: 6624 """ 6625 Compute the slice indexer for input labels and step. 6626 (...) 6660 slice(1, 3, None) 6661 """ -> 6662 start_slice, end_slice = self.slice_locs(start, end, step=step) 6664 # return a slice 6665 if not is_scalar(start_slice): File ~/work/pandas/pandas/pandas/core/indexes/base.py:6879, in Index.slice_locs(self, start, end, step) 6877 start_slice = None 6878 if start is not None: -> 6879 start_slice = self.get_slice_bound(start, "left") 6880 if start_slice is None: 6881 start_slice = 0 File ~/work/pandas/pandas/pandas/core/indexes/base.py:6794, in Index.get_slice_bound(self, label, side) 6790 original_label = label 6792 # For datetime indices label may be a string that has to be converted 6793 # to datetime boundary according to its resolution. -> 6794 label = self._maybe_cast_slice_bound(label, side) 6796 # we need to look up the label 6797 try: File ~/work/pandas/pandas/pandas/core/indexes/datetimes.py:642, in DatetimeIndex._maybe_cast_slice_bound(self, label, side) 637 if isinstance(label, dt.date) and not isinstance(label, dt.datetime): 638 # Pandas supports slicing with dates, treated as datetimes at midnight. 639 # https://github.com/pandas-dev/pandas/issues/31501 640 label = Timestamp(label).to_pydatetime() --> 642 label = super()._maybe_cast_slice_bound(label, side) 643 self._data._assert_tzawareness_compat(label) 644 return Timestamp(label) File ~/work/pandas/pandas/pandas/core/indexes/datetimelike.py:378, in DatetimeIndexOpsMixin._maybe_cast_slice_bound(self, label, side) 376 return lower if side == "left" else upper 377 elif not isinstance(label, self._data._recognized_scalars): --> 378 self._raise_invalid_indexer("slice", label) 380 return label File ~/work/pandas/pandas/pandas/core/indexes/base.py:4301, in Index._raise_invalid_indexer(self, form, key, reraise) 4299 if reraise is not lib.no_default: 4300 raise TypeError(msg) from reraise -> 4301 raise TypeError(msg) TypeError: cannot do slice indexing on DatetimeIndex with these indexers [2] of type int
切片中的類似字串可以轉換為索引類型,並導致自然切片。
In [44]: dfl.loc['20130102':'20130104']
Out[44]:
A B C D
2013-01-02 0.357021 -0.674600 -1.776904 -0.968914
2013-01-03 -1.294524 0.413738 0.276662 -0.472035
2013-01-04 -0.013960 -0.362543 -0.006154 -0.923061
pandas 提供一系列方法,以便進行純粹基於標籤的索引。這是一個嚴格的基於包含的協定。所要求的每個標籤都必須在索引中,否則會引發 KeyError。在切片時,如果存在於索引中,則開始邊界和停止邊界都包含在內。整數是有效的標籤,但它們指的是標籤而不是位置。
.loc 屬性是主要的存取方法。以下是有效的輸入
單一標籤,例如
5或'a'(請注意,5被解釋為索引的標籤。此用法不是沿著索引的整數位置。)標籤清單或陣列
['a', 'b', 'c']。包含標籤
'a':'f'的切片物件(請注意,與通常的 Python 切片相反,開始和停止都包含在內,如果存在於索引中!請參閱 使用標籤切片。一個布林陣列。
一個
callable,請參閱 透過 Callable 進行選取。
In [45]: s1 = pd.Series(np.random.randn(6), index=list('abcdef'))
In [46]: s1
Out[46]:
a 1.431256
b 1.340309
c -1.170299
d -0.226169
e 0.410835
f 0.813850
dtype: float64
In [47]: s1.loc['c':]
Out[47]:
c -1.170299
d -0.226169
e 0.410835
f 0.813850
dtype: float64
In [48]: s1.loc['b']
Out[48]: 1.3403088497993827
請注意設定也適用
In [49]: s1.loc['c':] = 0
In [50]: s1
Out[50]:
a 1.431256
b 1.340309
c 0.000000
d 0.000000
e 0.000000
f 0.000000
dtype: float64
使用資料框
In [51]: df1 = pd.DataFrame(np.random.randn(6, 4),
....: index=list('abcdef'),
....: columns=list('ABCD'))
....:
In [52]: df1
Out[52]:
A B C D
a 0.132003 -0.827317 -0.076467 -1.187678
b 1.130127 -1.436737 -1.413681 1.607920
c 1.024180 0.569605 0.875906 -2.211372
d 0.974466 -2.006747 -0.410001 -0.078638
e 0.545952 -1.219217 -1.226825 0.769804
f -1.281247 -0.727707 -0.121306 -0.097883
In [53]: df1.loc[['a', 'b', 'd'], :]
Out[53]:
A B C D
a 0.132003 -0.827317 -0.076467 -1.187678
b 1.130127 -1.436737 -1.413681 1.607920
d 0.974466 -2.006747 -0.410001 -0.078638
透過標籤切片存取
In [54]: df1.loc['d':, 'A':'C']
Out[54]:
A B C
d 0.974466 -2.006747 -0.410001
e 0.545952 -1.219217 -1.226825
f -1.281247 -0.727707 -0.121306
使用標籤取得橫切面(等同於 df.xs('a'))
In [55]: df1.loc['a']
Out[55]:
A 0.132003
B -0.827317
C -0.076467
D -1.187678
Name: a, dtype: float64
使用布林陣列取得值
In [56]: df1.loc['a'] > 0
Out[56]:
A True
B False
C False
D False
Name: a, dtype: bool
In [57]: df1.loc[:, df1.loc['a'] > 0]
Out[57]:
A
a 0.132003
b 1.130127
c 1.024180
d 0.974466
e 0.545952
f -1.281247
布林陣列中的 NA 值會傳播為 False
In [58]: mask = pd.array([True, False, True, False, pd.NA, False], dtype="boolean")
In [59]: mask
Out[59]:
<BooleanArray>
[True, False, True, False, <NA>, False]
Length: 6, dtype: boolean
In [60]: df1[mask]
Out[60]:
A B C D
a 0.132003 -0.827317 -0.076467 -1.187678
c 1.024180 0.569605 0.875906 -2.211372
明確取得值
# this is also equivalent to ``df1.at['a','A']``
In [61]: df1.loc['a', 'A']
Out[61]: 0.13200317033032932
使用標籤切片#
當使用 .loc 搭配切片時,如果開始和停止標籤都存在於索引中,則會傳回位於兩個標籤之間(包含它們)的元素
In [62]: s = pd.Series(list('abcde'), index=[0, 3, 2, 5, 4])
In [63]: s.loc[3:5]
Out[63]:
3 b
2 c
5 d
dtype: object
如果兩個標籤中至少一個不存在,但索引已排序,並且可以與開始和停止標籤進行比較,則切片仍會按預期工作,方法是選擇排名介於兩者之間的標籤
In [64]: s.sort_index()
Out[64]:
0 a
2 c
3 b
4 e
5 d
dtype: object
In [65]: s.sort_index().loc[1:6]
Out[65]:
2 c
3 b
4 e
5 d
dtype: object
但是,如果兩個標籤中至少一個不存在且索引未排序,則會引發錯誤(因為這樣做在計算上會很昂貴,並且對於混合類型索引可能會產生歧義)。例如,在上述範例中,s.loc[1:6] 會引發 KeyError。
有關此行為背後的原因,請參閱 端點包含在內。
In [66]: s = pd.Series(list('abcdef'), index=[0, 3, 2, 5, 4, 2])
In [67]: s.loc[3:5]
Out[67]:
3 b
2 c
5 d
dtype: object
此外,如果索引具有重複標籤且開始或停止標籤重複,則會引發錯誤。例如,在上述範例中,s.loc[2:5] 會引發 KeyError。
有關重複標籤的更多資訊,請參閱 重複標籤。
依位置選取#
警告
設定作業是否傳回複製或參考,可能取決於上下文。這有時稱為 連鎖 指派,應避免使用。請參閱 傳回檢視與複製。
pandas 提供一組方法,以便取得純粹基於整數的索引。語意緊密遵循 Python 和 NumPy 切片。這些是 0 為基礎 索引。在切片時,開始邊界包含在內,而上界不包含在內。嘗試使用非整數,即使是有效的標籤,也會引發 IndexError。
.iloc 屬性是主要的存取方法。下列是有效的輸入
整數,例如
5。整數清單或陣列
[4, 3, 0]。包含整數的切片物件
1:7。一個布林陣列。
一個
callable,請參閱 透過 Callable 進行選取。包含列 (和欄) 索引的元組,其元素為以上類型之一。
In [68]: s1 = pd.Series(np.random.randn(5), index=list(range(0, 10, 2)))
In [69]: s1
Out[69]:
0 0.695775
2 0.341734
4 0.959726
6 -1.110336
8 -0.619976
dtype: float64
In [70]: s1.iloc[:3]
Out[70]:
0 0.695775
2 0.341734
4 0.959726
dtype: float64
In [71]: s1.iloc[3]
Out[71]: -1.110336102891167
請注意設定也適用
In [72]: s1.iloc[:3] = 0
In [73]: s1
Out[73]:
0 0.000000
2 0.000000
4 0.000000
6 -1.110336
8 -0.619976
dtype: float64
使用資料框
In [74]: df1 = pd.DataFrame(np.random.randn(6, 4),
....: index=list(range(0, 12, 2)),
....: columns=list(range(0, 8, 2)))
....:
In [75]: df1
Out[75]:
0 2 4 6
0 0.149748 -0.732339 0.687738 0.176444
2 0.403310 -0.154951 0.301624 -2.179861
4 -1.369849 -0.954208 1.462696 -1.743161
6 -0.826591 -0.345352 1.314232 0.690579
8 0.995761 2.396780 0.014871 3.357427
10 -0.317441 -1.236269 0.896171 -0.487602
透過整數切片選擇
In [76]: df1.iloc[:3]
Out[76]:
0 2 4 6
0 0.149748 -0.732339 0.687738 0.176444
2 0.403310 -0.154951 0.301624 -2.179861
4 -1.369849 -0.954208 1.462696 -1.743161
In [77]: df1.iloc[1:5, 2:4]
Out[77]:
4 6
2 0.301624 -2.179861
4 1.462696 -1.743161
6 1.314232 0.690579
8 0.014871 3.357427
透過整數清單選擇
In [78]: df1.iloc[[1, 3, 5], [1, 3]]
Out[78]:
2 6
2 -0.154951 -2.179861
6 -0.345352 0.690579
10 -1.236269 -0.487602
In [79]: df1.iloc[1:3, :]
Out[79]:
0 2 4 6
2 0.403310 -0.154951 0.301624 -2.179861
4 -1.369849 -0.954208 1.462696 -1.743161
In [80]: df1.iloc[:, 1:3]
Out[80]:
2 4
0 -0.732339 0.687738
2 -0.154951 0.301624
4 -0.954208 1.462696
6 -0.345352 1.314232
8 2.396780 0.014871
10 -1.236269 0.896171
# this is also equivalent to ``df1.iat[1,1]``
In [81]: df1.iloc[1, 1]
Out[81]: -0.1549507744249032
使用整數位置取得橫切面 (等同於 df.xs(1))
In [82]: df1.iloc[1]
Out[82]:
0 0.403310
2 -0.154951
4 0.301624
6 -2.179861
Name: 2, dtype: float64
超出範圍的切片索引會像在 Python/NumPy 中一樣正常處理。
# these are allowed in Python/NumPy.
In [83]: x = list('abcdef')
In [84]: x
Out[84]: ['a', 'b', 'c', 'd', 'e', 'f']
In [85]: x[4:10]
Out[85]: ['e', 'f']
In [86]: x[8:10]
Out[86]: []
In [87]: s = pd.Series(x)
In [88]: s
Out[88]:
0 a
1 b
2 c
3 d
4 e
5 f
dtype: object
In [89]: s.iloc[4:10]
Out[89]:
4 e
5 f
dtype: object
In [90]: s.iloc[8:10]
Out[90]: Series([], dtype: object)
請注意,使用超出邊界的切片可能會導致軸為空 (例如,傳回空的 DataFrame)。
In [91]: dfl = pd.DataFrame(np.random.randn(5, 2), columns=list('AB'))
In [92]: dfl
Out[92]:
A B
0 -0.082240 -2.182937
1 0.380396 0.084844
2 0.432390 1.519970
3 -0.493662 0.600178
4 0.274230 0.132885
In [93]: dfl.iloc[:, 2:3]
Out[93]:
Empty DataFrame
Columns: []
Index: [0, 1, 2, 3, 4]
In [94]: dfl.iloc[:, 1:3]
Out[94]:
B
0 -2.182937
1 0.084844
2 1.519970
3 0.600178
4 0.132885
In [95]: dfl.iloc[4:6]
Out[95]:
A B
4 0.27423 0.132885
超出邊界的單一索引器會引發 IndexError。任何元素超出邊界的索引器清單會引發 IndexError。
In [96]: dfl.iloc[[4, 5, 6]]
---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
File ~/work/pandas/pandas/pandas/core/indexing.py:1714, in _iLocIndexer._get_list_axis(self, key, axis)
1713 try:
-> 1714 return self.obj._take_with_is_copy(key, axis=axis)
1715 except IndexError as err:
1716 # re-raise with different error message, e.g. test_getitem_ndarray_3d
File ~/work/pandas/pandas/pandas/core/generic.py:4150, in NDFrame._take_with_is_copy(self, indices, axis)
4141 """
4142 Internal version of the `take` method that sets the `_is_copy`
4143 attribute to keep track of the parent dataframe (using in indexing
(...)
4148 See the docstring of `take` for full explanation of the parameters.
4149 """
-> 4150 result = self.take(indices=indices, axis=axis)
4151 # Maybe set copy if we didn't actually change the index.
File ~/work/pandas/pandas/pandas/core/generic.py:4130, in NDFrame.take(self, indices, axis, **kwargs)
4126 indices = np.arange(
4127 indices.start, indices.stop, indices.step, dtype=np.intp
4128 )
-> 4130 new_data = self._mgr.take(
4131 indices,
4132 axis=self._get_block_manager_axis(axis),
4133 verify=True,
4134 )
4135 return self._constructor_from_mgr(new_data, axes=new_data.axes).__finalize__(
4136 self, method="take"
4137 )
File ~/work/pandas/pandas/pandas/core/internals/managers.py:891, in BaseBlockManager.take(self, indexer, axis, verify)
890 n = self.shape[axis]
--> 891 indexer = maybe_convert_indices(indexer, n, verify=verify)
893 new_labels = self.axes[axis].take(indexer)
File ~/work/pandas/pandas/pandas/core/indexers/utils.py:282, in maybe_convert_indices(indices, n, verify)
281 if mask.any():
--> 282 raise IndexError("indices are out-of-bounds")
283 return indices
IndexError: indices are out-of-bounds
The above exception was the direct cause of the following exception:
IndexError Traceback (most recent call last)
Cell In[96], line 1
----> 1 dfl.iloc[[4, 5, 6]]
File ~/work/pandas/pandas/pandas/core/indexing.py:1191, in _LocationIndexer.__getitem__(self, key)
1189 maybe_callable = com.apply_if_callable(key, self.obj)
1190 maybe_callable = self._check_deprecated_callable_usage(key, maybe_callable)
-> 1191 return self._getitem_axis(maybe_callable, axis=axis)
File ~/work/pandas/pandas/pandas/core/indexing.py:1743, in _iLocIndexer._getitem_axis(self, key, axis)
1741 # a list of integers
1742 elif is_list_like_indexer(key):
-> 1743 return self._get_list_axis(key, axis=axis)
1745 # a single integer
1746 else:
1747 key = item_from_zerodim(key)
File ~/work/pandas/pandas/pandas/core/indexing.py:1717, in _iLocIndexer._get_list_axis(self, key, axis)
1714 return self.obj._take_with_is_copy(key, axis=axis)
1715 except IndexError as err:
1716 # re-raise with different error message, e.g. test_getitem_ndarray_3d
-> 1717 raise IndexError("positional indexers are out-of-bounds") from err
IndexError: positional indexers are out-of-bounds
In [97]: dfl.iloc[:, 4]
---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
Cell In[97], line 1
----> 1 dfl.iloc[:, 4]
File ~/work/pandas/pandas/pandas/core/indexing.py:1184, in _LocationIndexer.__getitem__(self, key)
1182 if self._is_scalar_access(key):
1183 return self.obj._get_value(*key, takeable=self._takeable)
-> 1184 return self._getitem_tuple(key)
1185 else:
1186 # we by definition only have the 0th axis
1187 axis = self.axis or 0
File ~/work/pandas/pandas/pandas/core/indexing.py:1690, in _iLocIndexer._getitem_tuple(self, tup)
1689 def _getitem_tuple(self, tup: tuple):
-> 1690 tup = self._validate_tuple_indexer(tup)
1691 with suppress(IndexingError):
1692 return self._getitem_lowerdim(tup)
File ~/work/pandas/pandas/pandas/core/indexing.py:966, in _LocationIndexer._validate_tuple_indexer(self, key)
964 for i, k in enumerate(key):
965 try:
--> 966 self._validate_key(k, i)
967 except ValueError as err:
968 raise ValueError(
969 "Location based indexing can only have "
970 f"[{self._valid_types}] types"
971 ) from err
File ~/work/pandas/pandas/pandas/core/indexing.py:1592, in _iLocIndexer._validate_key(self, key, axis)
1590 return
1591 elif is_integer(key):
-> 1592 self._validate_integer(key, axis)
1593 elif isinstance(key, tuple):
1594 # a tuple should already have been caught by this point
1595 # so don't treat a tuple as a valid indexer
1596 raise IndexingError("Too many indexers")
File ~/work/pandas/pandas/pandas/core/indexing.py:1685, in _iLocIndexer._validate_integer(self, key, axis)
1683 len_axis = len(self.obj._get_axis(axis))
1684 if key >= len_axis or key < -len_axis:
-> 1685 raise IndexError("single positional indexer is out-of-bounds")
IndexError: single positional indexer is out-of-bounds
透過可呼叫函數選擇#
.loc、.iloc,以及 [] 索引可以接受 callable 作為索引器。callable 必須是具有單一參數 (呼叫的 Series 或 DataFrame) 的函數,並傳回有效的索引輸出。
注意
對於 .iloc 索引,不支援從可呼叫函數傳回元組,因為列和欄索引的元組解構發生在套用可呼叫函數之前。
In [98]: df1 = pd.DataFrame(np.random.randn(6, 4),
....: index=list('abcdef'),
....: columns=list('ABCD'))
....:
In [99]: df1
Out[99]:
A B C D
a -0.023688 2.410179 1.450520 0.206053
b -0.251905 -2.213588 1.063327 1.266143
c 0.299368 -0.863838 0.408204 -1.048089
d -0.025747 -0.988387 0.094055 1.262731
e 1.289997 0.082423 -0.055758 0.536580
f -0.489682 0.369374 -0.034571 -2.484478
In [100]: df1.loc[lambda df: df['A'] > 0, :]
Out[100]:
A B C D
c 0.299368 -0.863838 0.408204 -1.048089
e 1.289997 0.082423 -0.055758 0.536580
In [101]: df1.loc[:, lambda df: ['A', 'B']]
Out[101]:
A B
a -0.023688 2.410179
b -0.251905 -2.213588
c 0.299368 -0.863838
d -0.025747 -0.988387
e 1.289997 0.082423
f -0.489682 0.369374
In [102]: df1.iloc[:, lambda df: [0, 1]]
Out[102]:
A B
a -0.023688 2.410179
b -0.251905 -2.213588
c 0.299368 -0.863838
d -0.025747 -0.988387
e 1.289997 0.082423
f -0.489682 0.369374
In [103]: df1[lambda df: df.columns[0]]
Out[103]:
a -0.023688
b -0.251905
c 0.299368
d -0.025747
e 1.289997
f -0.489682
Name: A, dtype: float64
您可以在 Series 中使用可呼叫函數索引。
In [104]: df1['A'].loc[lambda s: s > 0]
Out[104]:
c 0.299368
e 1.289997
Name: A, dtype: float64
使用這些方法/索引器,您可以在不使用暫時變數的情況下串連資料選取作業。
In [105]: bb = pd.read_csv('data/baseball.csv', index_col='id')
In [106]: (bb.groupby(['year', 'team']).sum(numeric_only=True)
.....: .loc[lambda df: df['r'] > 100])
.....:
Out[106]:
stint g ab r h X2b ... so ibb hbp sh sf gidp
year team ...
2007 CIN 6 379 745 101 203 35 ... 127.0 14.0 1.0 1.0 15.0 18.0
DET 5 301 1062 162 283 54 ... 176.0 3.0 10.0 4.0 8.0 28.0
HOU 4 311 926 109 218 47 ... 212.0 3.0 9.0 16.0 6.0 17.0
LAN 11 413 1021 153 293 61 ... 141.0 8.0 9.0 3.0 8.0 29.0
NYN 13 622 1854 240 509 101 ... 310.0 24.0 23.0 18.0 15.0 48.0
SFN 5 482 1305 198 337 67 ... 188.0 51.0 8.0 16.0 6.0 41.0
TEX 2 198 729 115 200 40 ... 140.0 4.0 5.0 2.0 8.0 16.0
TOR 4 459 1408 187 378 96 ... 265.0 16.0 12.0 4.0 16.0 38.0
[8 rows x 18 columns]
結合位置和標籤式索引#
如果您希望從「A」欄中的索引取得第 0 個和第 2 個元素,您可以執行
In [107]: dfd = pd.DataFrame({'A': [1, 2, 3],
.....: 'B': [4, 5, 6]},
.....: index=list('abc'))
.....:
In [108]: dfd
Out[108]:
A B
a 1 4
b 2 5
c 3 6
In [109]: dfd.loc[dfd.index[[0, 2]], 'A']
Out[109]:
a 1
c 3
Name: A, dtype: int64
這也可以使用 .iloc 表示,透過明確取得索引器上的位置,並使用位置索引來選取項目。
In [110]: dfd.iloc[[0, 2], dfd.columns.get_loc('A')]
Out[110]:
a 1
c 3
Name: A, dtype: int64
若要取得多個索引器,請使用 .get_indexer
In [111]: dfd.iloc[[0, 2], dfd.columns.get_indexer(['A', 'B'])]
Out[111]:
A B
a 1 4
c 3 6
重新編制索引#
慣用的方式是透過 .reindex() 來選取可能找不到的元素。另請參閱 重新編制索引 一節。
In [112]: s = pd.Series([1, 2, 3])
In [113]: s.reindex([1, 2, 3])
Out[113]:
1 2.0
2 3.0
3 NaN
dtype: float64
或者,如果您只想選取有效的金鑰,下列方法是慣用且有效的;它保證會保留選取項目的資料型態。
In [114]: labels = [1, 2, 3]
In [115]: s.loc[s.index.intersection(labels)]
Out[115]:
1 2
2 3
dtype: int64
重複的索引會引發 .reindex()
In [116]: s = pd.Series(np.arange(4), index=['a', 'a', 'b', 'c'])
In [117]: labels = ['c', 'd']
In [118]: s.reindex(labels)
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
Cell In[118], line 1
----> 1 s.reindex(labels)
File ~/work/pandas/pandas/pandas/core/series.py:5144, in Series.reindex(self, index, axis, method, copy, level, fill_value, limit, tolerance)
5127 @doc(
5128 NDFrame.reindex, # type: ignore[has-type]
5129 klass=_shared_doc_kwargs["klass"],
(...)
5142 tolerance=None,
5143 ) -> Series:
-> 5144 return super().reindex(
5145 index=index,
5146 method=method,
5147 copy=copy,
5148 level=level,
5149 fill_value=fill_value,
5150 limit=limit,
5151 tolerance=tolerance,
5152 )
File ~/work/pandas/pandas/pandas/core/generic.py:5607, in NDFrame.reindex(self, labels, index, columns, axis, method, copy, level, fill_value, limit, tolerance)
5604 return self._reindex_multi(axes, copy, fill_value)
5606 # perform the reindex on the axes
-> 5607 return self._reindex_axes(
5608 axes, level, limit, tolerance, method, fill_value, copy
5609 ).__finalize__(self, method="reindex")
File ~/work/pandas/pandas/pandas/core/generic.py:5630, in NDFrame._reindex_axes(self, axes, level, limit, tolerance, method, fill_value, copy)
5627 continue
5629 ax = self._get_axis(a)
-> 5630 new_index, indexer = ax.reindex(
5631 labels, level=level, limit=limit, tolerance=tolerance, method=method
5632 )
5634 axis = self._get_axis_number(a)
5635 obj = obj._reindex_with_indexers(
5636 {axis: [new_index, indexer]},
5637 fill_value=fill_value,
5638 copy=copy,
5639 allow_dups=False,
5640 )
File ~/work/pandas/pandas/pandas/core/indexes/base.py:4429, in Index.reindex(self, target, method, level, limit, tolerance)
4426 raise ValueError("cannot handle a non-unique multi-index!")
4427 elif not self.is_unique:
4428 # GH#42568
-> 4429 raise ValueError("cannot reindex on an axis with duplicate labels")
4430 else:
4431 indexer, _ = self.get_indexer_non_unique(target)
ValueError: cannot reindex on an axis with duplicate labels
一般來說,您可以將想要的標籤與目前的軸相交,然後重新編制索引。
In [119]: s.loc[s.index.intersection(labels)].reindex(labels)
Out[119]:
c 3.0
d NaN
dtype: float64
但是,如果產生的索引重複,仍然會引發錯誤。
In [120]: labels = ['a', 'd']
In [121]: s.loc[s.index.intersection(labels)].reindex(labels)
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
Cell In[121], line 1
----> 1 s.loc[s.index.intersection(labels)].reindex(labels)
File ~/work/pandas/pandas/pandas/core/series.py:5144, in Series.reindex(self, index, axis, method, copy, level, fill_value, limit, tolerance)
5127 @doc(
5128 NDFrame.reindex, # type: ignore[has-type]
5129 klass=_shared_doc_kwargs["klass"],
(...)
5142 tolerance=None,
5143 ) -> Series:
-> 5144 return super().reindex(
5145 index=index,
5146 method=method,
5147 copy=copy,
5148 level=level,
5149 fill_value=fill_value,
5150 limit=limit,
5151 tolerance=tolerance,
5152 )
File ~/work/pandas/pandas/pandas/core/generic.py:5607, in NDFrame.reindex(self, labels, index, columns, axis, method, copy, level, fill_value, limit, tolerance)
5604 return self._reindex_multi(axes, copy, fill_value)
5606 # perform the reindex on the axes
-> 5607 return self._reindex_axes(
5608 axes, level, limit, tolerance, method, fill_value, copy
5609 ).__finalize__(self, method="reindex")
File ~/work/pandas/pandas/pandas/core/generic.py:5630, in NDFrame._reindex_axes(self, axes, level, limit, tolerance, method, fill_value, copy)
5627 continue
5629 ax = self._get_axis(a)
-> 5630 new_index, indexer = ax.reindex(
5631 labels, level=level, limit=limit, tolerance=tolerance, method=method
5632 )
5634 axis = self._get_axis_number(a)
5635 obj = obj._reindex_with_indexers(
5636 {axis: [new_index, indexer]},
5637 fill_value=fill_value,
5638 copy=copy,
5639 allow_dups=False,
5640 )
File ~/work/pandas/pandas/pandas/core/indexes/base.py:4429, in Index.reindex(self, target, method, level, limit, tolerance)
4426 raise ValueError("cannot handle a non-unique multi-index!")
4427 elif not self.is_unique:
4428 # GH#42568
-> 4429 raise ValueError("cannot reindex on an axis with duplicate labels")
4430 else:
4431 indexer, _ = self.get_indexer_non_unique(target)
ValueError: cannot reindex on an axis with duplicate labels
選取隨機樣本#
使用 sample() 方法從 Series 或 DataFrame 中隨機選取列或欄。此方法預設會取樣列,並接受要傳回的特定列/欄數量,或列的分數。
In [122]: s = pd.Series([0, 1, 2, 3, 4, 5])
# When no arguments are passed, returns 1 row.
In [123]: s.sample()
Out[123]:
4 4
dtype: int64
# One may specify either a number of rows:
In [124]: s.sample(n=3)
Out[124]:
0 0
4 4
1 1
dtype: int64
# Or a fraction of the rows:
In [125]: s.sample(frac=0.5)
Out[125]:
5 5
3 3
1 1
dtype: int64
預設情況下,sample 會最多傳回每一列一次,但也可以使用 replace 選項進行替換取樣
In [126]: s = pd.Series([0, 1, 2, 3, 4, 5])
# Without replacement (default):
In [127]: s.sample(n=6, replace=False)
Out[127]:
0 0
1 1
5 5
3 3
2 2
4 4
dtype: int64
# With replacement:
In [128]: s.sample(n=6, replace=True)
Out[128]:
0 0
4 4
3 3
2 2
4 4
4 4
dtype: int64
預設情況下,每一列都有相同的機率被選取,但如果你希望列有不同的機率,你可以傳遞 sample 函數抽樣權重為 weights。這些權重可以是清單、NumPy 陣列或 Series,但它們必須與你抽樣的物件長度相同。遺失值將被視為權重為零,且不允許有無限大值。如果權重總和不為 1,它們將透過將所有權重除以權重總和來重新正規化。例如
In [129]: s = pd.Series([0, 1, 2, 3, 4, 5])
In [130]: example_weights = [0, 0, 0.2, 0.2, 0.2, 0.4]
In [131]: s.sample(n=3, weights=example_weights)
Out[131]:
5 5
4 4
3 3
dtype: int64
# Weights will be re-normalized automatically
In [132]: example_weights2 = [0.5, 0, 0, 0, 0, 0]
In [133]: s.sample(n=1, weights=example_weights2)
Out[133]:
0 0
dtype: int64
套用至資料框時,你可以使用資料框的欄位作為抽樣權重(前提是你抽樣的是列而不是欄),方法是簡單地傳遞欄位名稱為字串。
In [134]: df2 = pd.DataFrame({'col1': [9, 8, 7, 6],
.....: 'weight_column': [0.5, 0.4, 0.1, 0]})
.....:
In [135]: df2.sample(n=3, weights='weight_column')
Out[135]:
col1 weight_column
1 8 0.4
0 9 0.5
2 7 0.1
sample 也允許使用者使用 axis 參數抽樣欄而不是列。
In [136]: df3 = pd.DataFrame({'col1': [1, 2, 3], 'col2': [2, 3, 4]})
In [137]: df3.sample(n=1, axis=1)
Out[137]:
col1
0 1
1 2
2 3
最後,你也可以使用 random_state 參數為 sample 的亂數產生器設定種子,它會接受整數(作為種子)或 NumPy RandomState 物件。
In [138]: df4 = pd.DataFrame({'col1': [1, 2, 3], 'col2': [2, 3, 4]})
# With a given seed, the sample will always draw the same rows.
In [139]: df4.sample(n=2, random_state=2)
Out[139]:
col1 col2
2 3 4
1 2 3
In [140]: df4.sample(n=2, random_state=2)
Out[140]:
col1 col2
2 3 4
1 2 3
使用擴充設定#
當設定該軸不存在的鍵時,.loc/[] 作業可以執行擴充。
在 Series 案例中,這實際上是附加作業。
In [141]: se = pd.Series([1, 2, 3])
In [142]: se
Out[142]:
0 1
1 2
2 3
dtype: int64
In [143]: se[5] = 5.
In [144]: se
Out[144]:
0 1.0
1 2.0
2 3.0
5 5.0
dtype: float64
資料框可以透過 .loc 在任一軸上擴充。
In [145]: dfi = pd.DataFrame(np.arange(6).reshape(3, 2),
.....: columns=['A', 'B'])
.....:
In [146]: dfi
Out[146]:
A B
0 0 1
1 2 3
2 4 5
In [147]: dfi.loc[:, 'C'] = dfi.loc[:, 'A']
In [148]: dfi
Out[148]:
A B C
0 0 1 0
1 2 3 2
2 4 5 4
這類似於 append 對 DataFrame 的操作。
In [149]: dfi.loc[3] = 5
In [150]: dfi
Out[150]:
A B C
0 0 1 0
1 2 3 2
2 4 5 4
3 5 5 5
快速取得和設定純量值#
由於使用 [] 編製索引時必須處理許多情況(單一標籤存取、切片、布林索引等),因此它會花費一些時間來找出您要詢問的內容。如果您只想存取純量值,最快的做法是使用 at 和 iat 方法,這些方法已實作在所有資料結構中。
類似於 loc,at 提供基於標籤的純量查詢,而 iat 提供基於整數的查詢,類似於 iloc
In [151]: s.iat[5]
Out[151]: 5
In [152]: df.at[dates[5], 'A']
Out[152]: 0.1136484096888855
In [153]: df.iat[3, 0]
Out[153]: -0.7067711336300845
您也可以使用這些相同的索引器來設定。
In [154]: df.at[dates[5], 'E'] = 7
In [155]: df.iat[3, 0] = 7
如果索引器不存在,at 可能會在原地擴充物件,如上所述。
In [156]: df.at[dates[-1] + pd.Timedelta('1 day'), 0] = 7
In [157]: df
Out[157]:
A B C D E 0
2000-01-01 -0.282863 0.469112 -1.509059 -1.135632 NaN NaN
2000-01-02 -0.173215 1.212112 0.119209 -1.044236 NaN NaN
2000-01-03 -2.104569 -0.861849 -0.494929 1.071804 NaN NaN
2000-01-04 7.000000 0.721555 -1.039575 0.271860 NaN NaN
2000-01-05 0.567020 -0.424972 0.276232 -1.087401 NaN NaN
2000-01-06 0.113648 -0.673690 -1.478427 0.524988 7.0 NaN
2000-01-07 0.577046 0.404705 -1.715002 -1.039268 NaN NaN
2000-01-08 -1.157892 -0.370647 -1.344312 0.844885 NaN NaN
2000-01-09 NaN NaN NaN NaN NaN 7.0
布林索引#
另一個常見的運算為使用布林向量來篩選資料。運算子有:| 表示 or,& 表示 and,~ 表示 not。這些運算子必須使用括號進行分組,因為預設情況下,Python 會將類似 df['A'] > 2 & df['B'] < 3 的表達式評估為 df['A'] > (2 & df['B']) < 3,而想要的評估順序為 (df['A'] > 2) & (df['B'] < 3)。
使用布林向量來索引 Series 的運作方式與在 NumPy ndarray 中完全相同
In [158]: s = pd.Series(range(-3, 4))
In [159]: s
Out[159]:
0 -3
1 -2
2 -1
3 0
4 1
5 2
6 3
dtype: int64
In [160]: s[s > 0]
Out[160]:
4 1
5 2
6 3
dtype: int64
In [161]: s[(s < -1) | (s > 0.5)]
Out[161]:
0 -3
1 -2
4 1
5 2
6 3
dtype: int64
In [162]: s[~(s < 0)]
Out[162]:
3 0
4 1
5 2
6 3
dtype: int64
您可以使用與 DataFrame 索引長度相同的布林向量從 DataFrame 中選取列(例如,從 DataFrame 的某個欄位衍生的資料)
In [163]: df[df['A'] > 0]
Out[163]:
A B C D E 0
2000-01-04 7.000000 0.721555 -1.039575 0.271860 NaN NaN
2000-01-05 0.567020 -0.424972 0.276232 -1.087401 NaN NaN
2000-01-06 0.113648 -0.673690 -1.478427 0.524988 7.0 NaN
2000-01-07 0.577046 0.404705 -1.715002 -1.039268 NaN NaN
清單推導式和 Series 的 map 方法也可以用來產生更複雜的條件
In [164]: df2 = pd.DataFrame({'a': ['one', 'one', 'two', 'three', 'two', 'one', 'six'],
.....: 'b': ['x', 'y', 'y', 'x', 'y', 'x', 'x'],
.....: 'c': np.random.randn(7)})
.....:
# only want 'two' or 'three'
In [165]: criterion = df2['a'].map(lambda x: x.startswith('t'))
In [166]: df2[criterion]
Out[166]:
a b c
2 two y 0.041290
3 three x 0.361719
4 two y -0.238075
# equivalent but slower
In [167]: df2[[x.startswith('t') for x in df2['a']]]
Out[167]:
a b c
2 two y 0.041290
3 three x 0.361719
4 two y -0.238075
# Multiple criteria
In [168]: df2[criterion & (df2['b'] == 'x')]
Out[168]:
a b c
3 three x 0.361719
使用選取方法 依標籤選取、依位置選取 和 進階索引,您可以使用布林向量結合其他索引式來沿著多個軸選取。
In [169]: df2.loc[criterion & (df2['b'] == 'x'), 'b':'c']
Out[169]:
b c
3 x 0.361719
警告
iloc 支援兩種布林索引。如果索引器是布林 Series,將會產生錯誤。例如,在下列範例中,df.iloc[s.values, 1] 是正確的。布林索引器是一個陣列。但 df.iloc[s, 1] 會產生 ValueError。
In [170]: df = pd.DataFrame([[1, 2], [3, 4], [5, 6]],
.....: index=list('abc'),
.....: columns=['A', 'B'])
.....:
In [171]: s = (df['A'] > 2)
In [172]: s
Out[172]:
a False
b True
c True
Name: A, dtype: bool
In [173]: df.loc[s, 'B']
Out[173]:
b 4
c 6
Name: B, dtype: int64
In [174]: df.iloc[s.values, 1]
Out[174]:
b 4
c 6
Name: B, dtype: int64
使用 isin 進行索引#
考慮 Series 的 isin() 方法,它會傳回一個布林向量,其中 Series 元素存在於傳遞清單中的任何位置,則為 true。這讓您可以選取其中一或多個欄位具有您要的值的列
In [175]: s = pd.Series(np.arange(5), index=np.arange(5)[::-1], dtype='int64')
In [176]: s
Out[176]:
4 0
3 1
2 2
1 3
0 4
dtype: int64
In [177]: s.isin([2, 4, 6])
Out[177]:
4 False
3 False
2 True
1 False
0 True
dtype: bool
In [178]: s[s.isin([2, 4, 6])]
Out[178]:
2 2
0 4
dtype: int64
相同的 Index 物件方法可用,而且在您不知道所尋找標籤中哪些實際上存在時,這會很有用
In [179]: s[s.index.isin([2, 4, 6])]
Out[179]:
4 0
2 2
dtype: int64
# compare it to the following
In [180]: s.reindex([2, 4, 6])
Out[180]:
2 2.0
4 0.0
6 NaN
dtype: float64
此外,MultiIndex 允許選取一個不同的層級,以用於成員資格檢查
In [181]: s_mi = pd.Series(np.arange(6),
.....: index=pd.MultiIndex.from_product([[0, 1], ['a', 'b', 'c']]))
.....:
In [182]: s_mi
Out[182]:
0 a 0
b 1
c 2
1 a 3
b 4
c 5
dtype: int64
In [183]: s_mi.iloc[s_mi.index.isin([(1, 'a'), (2, 'b'), (0, 'c')])]
Out[183]:
0 c 2
1 a 3
dtype: int64
In [184]: s_mi.iloc[s_mi.index.isin(['a', 'c', 'e'], level=1)]
Out[184]:
0 a 0
c 2
1 a 3
c 5
dtype: int64
DataFrame 也有 isin() 方法。當呼叫 isin 時,傳遞一組值作為陣列或字典。如果值是陣列,isin 會傳回一個布林值的 DataFrame,其形狀與原始 DataFrame 相同,其中元素在值序列中時為 True。
In [185]: df = pd.DataFrame({'vals': [1, 2, 3, 4], 'ids': ['a', 'b', 'f', 'n'],
.....: 'ids2': ['a', 'n', 'c', 'n']})
.....:
In [186]: values = ['a', 'b', 1, 3]
In [187]: df.isin(values)
Out[187]:
vals ids ids2
0 True True True
1 False True False
2 True False False
3 False False False
通常您會想要將特定值與特定欄位配對。只要將值設為 dict,其中鍵是欄位,而值是您想要檢查的項目清單。
In [188]: values = {'ids': ['a', 'b'], 'vals': [1, 3]}
In [189]: df.isin(values)
Out[189]:
vals ids ids2
0 True True False
1 False True False
2 True False False
3 False False False
若要傳回布林值的 DataFrame,其中值不在原始 DataFrame 中,請使用 ~ 算子
In [190]: values = {'ids': ['a', 'b'], 'vals': [1, 3]}
In [191]: ~df.isin(values)
Out[191]:
vals ids ids2
0 False False True
1 True False True
2 False True True
3 True True True
將 DataFrame 的 isin 與 any() 和 all() 方法結合,以快速選取符合特定條件的資料子集。若要選取每一欄都符合其自身條件的列
In [192]: values = {'ids': ['a', 'b'], 'ids2': ['a', 'c'], 'vals': [1, 3]}
In [193]: row_mask = df.isin(values).all(1)
In [194]: df[row_mask]
Out[194]:
vals ids ids2
0 1 a a
where() 方法和遮罩#
通常使用布林向量從 Series 選取值會傳回資料的子集。若要保證選取的輸出與原始資料形狀相同,您可以在 Series
DataFrame 中使用 where 方法。
僅傳回已選取的列
In [195]: s[s > 0]
Out[195]:
3 1
2 2
1 3
0 4
dtype: int64
傳回與原始資料形狀相同的 Series
In [196]: s.where(s > 0)
Out[196]:
4 NaN
3 1.0
2 2.0
1 3.0
0 4.0
dtype: float64
現在,使用布林條件從 DataFrame 選取值也會保留輸入資料形狀。實作時會在幕後使用 where。下方的程式碼等同於 df.where(df < 0)。
In [197]: dates = pd.date_range('1/1/2000', periods=8)
In [198]: df = pd.DataFrame(np.random.randn(8, 4),
.....: index=dates, columns=['A', 'B', 'C', 'D'])
.....:
In [199]: df[df < 0]
Out[199]:
A B C D
2000-01-01 -2.104139 -1.309525 NaN NaN
2000-01-02 -0.352480 NaN -1.192319 NaN
2000-01-03 -0.864883 NaN -0.227870 NaN
2000-01-04 NaN -1.222082 NaN -1.233203
2000-01-05 NaN -0.605656 -1.169184 NaN
2000-01-06 NaN -0.948458 NaN -0.684718
2000-01-07 -2.670153 -0.114722 NaN -0.048048
2000-01-08 NaN NaN -0.048788 -0.808838
此外,where 會接受一個選用的 other 參數,用於替換傳回副本中條件為 False 的值。
In [200]: df.where(df < 0, -df)
Out[200]:
A B C D
2000-01-01 -2.104139 -1.309525 -0.485855 -0.245166
2000-01-02 -0.352480 -0.390389 -1.192319 -1.655824
2000-01-03 -0.864883 -0.299674 -0.227870 -0.281059
2000-01-04 -0.846958 -1.222082 -0.600705 -1.233203
2000-01-05 -0.669692 -0.605656 -1.169184 -0.342416
2000-01-06 -0.868584 -0.948458 -2.297780 -0.684718
2000-01-07 -2.670153 -0.114722 -0.168904 -0.048048
2000-01-08 -0.801196 -1.392071 -0.048788 -0.808838
您可能希望根據一些布林條件設定值。這可以用直覺的方式完成,如下所示
In [201]: s2 = s.copy()
In [202]: s2[s2 < 0] = 0
In [203]: s2
Out[203]:
4 0
3 1
2 2
1 3
0 4
dtype: int64
In [204]: df2 = df.copy()
In [205]: df2[df2 < 0] = 0
In [206]: df2
Out[206]:
A B C D
2000-01-01 0.000000 0.000000 0.485855 0.245166
2000-01-02 0.000000 0.390389 0.000000 1.655824
2000-01-03 0.000000 0.299674 0.000000 0.281059
2000-01-04 0.846958 0.000000 0.600705 0.000000
2000-01-05 0.669692 0.000000 0.000000 0.342416
2000-01-06 0.868584 0.000000 2.297780 0.000000
2000-01-07 0.000000 0.000000 0.168904 0.000000
2000-01-08 0.801196 1.392071 0.000000 0.000000
where 會傳回已修改的資料副本。
注意
與 DataFrame.where() 的簽章不同於 numpy.where()。大致上 df1.where(m, df2) 等同於 np.where(m, df1, df2)。
In [207]: df.where(df < 0, -df) == np.where(df < 0, df, -df)
Out[207]:
A B C D
2000-01-01 True True True True
2000-01-02 True True True True
2000-01-03 True True True True
2000-01-04 True True True True
2000-01-05 True True True True
2000-01-06 True True True True
2000-01-07 True True True True
2000-01-08 True True True True
對齊
此外,where 會對齊輸入的布林條件 (ndarray 或 DataFrame),以便進行部分選取設定。這類似於透過 .loc 進行部分設定 (但針對內容而不是軸標籤)。
In [208]: df2 = df.copy()
In [209]: df2[df2[1:4] > 0] = 3
In [210]: df2
Out[210]:
A B C D
2000-01-01 -2.104139 -1.309525 0.485855 0.245166
2000-01-02 -0.352480 3.000000 -1.192319 3.000000
2000-01-03 -0.864883 3.000000 -0.227870 3.000000
2000-01-04 3.000000 -1.222082 3.000000 -1.233203
2000-01-05 0.669692 -0.605656 -1.169184 0.342416
2000-01-06 0.868584 -0.948458 2.297780 -0.684718
2000-01-07 -2.670153 -0.114722 0.168904 -0.048048
2000-01-08 0.801196 1.392071 -0.048788 -0.808838
也可以接受 axis 和 level 參數,以便在執行 where 時對齊輸入。
In [211]: df2 = df.copy()
In [212]: df2.where(df2 > 0, df2['A'], axis='index')
Out[212]:
A B C D
2000-01-01 -2.104139 -2.104139 0.485855 0.245166
2000-01-02 -0.352480 0.390389 -0.352480 1.655824
2000-01-03 -0.864883 0.299674 -0.864883 0.281059
2000-01-04 0.846958 0.846958 0.600705 0.846958
2000-01-05 0.669692 0.669692 0.669692 0.342416
2000-01-06 0.868584 0.868584 2.297780 0.868584
2000-01-07 -2.670153 -2.670153 0.168904 -2.670153
2000-01-08 0.801196 1.392071 0.801196 0.801196
這等於(但比)以下內容更快。
In [213]: df2 = df.copy()
In [214]: df.apply(lambda x, y: x.where(x > 0, y), y=df['A'])
Out[214]:
A B C D
2000-01-01 -2.104139 -2.104139 0.485855 0.245166
2000-01-02 -0.352480 0.390389 -0.352480 1.655824
2000-01-03 -0.864883 0.299674 -0.864883 0.281059
2000-01-04 0.846958 0.846958 0.600705 0.846958
2000-01-05 0.669692 0.669692 0.669692 0.342416
2000-01-06 0.868584 0.868584 2.297780 0.868584
2000-01-07 -2.670153 -2.670153 0.168904 -2.670153
2000-01-08 0.801196 1.392071 0.801196 0.801196
where 可以接受一個可呼叫的條件和 other 參數。該函數必須帶有一個參數(呼叫的 Series 或 DataFrame),並返回有效的輸出作為條件和 other 參數。
In [215]: df3 = pd.DataFrame({'A': [1, 2, 3],
.....: 'B': [4, 5, 6],
.....: 'C': [7, 8, 9]})
.....:
In [216]: df3.where(lambda x: x > 4, lambda x: x + 10)
Out[216]:
A B C
0 11 14 7
1 12 5 8
2 13 6 9
遮罩#
mask() 是 where 的反向布林運算。
In [217]: s.mask(s >= 0)
Out[217]:
4 NaN
3 NaN
2 NaN
1 NaN
0 NaN
dtype: float64
In [218]: df.mask(df >= 0)
Out[218]:
A B C D
2000-01-01 -2.104139 -1.309525 NaN NaN
2000-01-02 -0.352480 NaN -1.192319 NaN
2000-01-03 -0.864883 NaN -0.227870 NaN
2000-01-04 NaN -1.222082 NaN -1.233203
2000-01-05 NaN -0.605656 -1.169184 NaN
2000-01-06 NaN -0.948458 NaN -0.684718
2000-01-07 -2.670153 -0.114722 NaN -0.048048
2000-01-08 NaN NaN -0.048788 -0.808838
使用 numpy() 有條件地設定擴充#
替代 where() 的方法是使用 numpy.where()。結合設定新欄位,您可以使用它來擴充 DataFrame,其中值是有條件地確定的。
考慮您在以下 DataFrame 中有兩個選擇。當第二欄有「Z」時,您希望將新欄位顏色設定為「綠色」。您可以執行下列操作
In [219]: df = pd.DataFrame({'col1': list('ABBC'), 'col2': list('ZZXY')})
In [220]: df['color'] = np.where(df['col2'] == 'Z', 'green', 'red')
In [221]: df
Out[221]:
col1 col2 color
0 A Z green
1 B Z green
2 B X red
3 C Y red
如果您有多個條件,可以使用 numpy.select() 來達成。假設對應於三個條件有三個顏色的選擇,並有一個第四個顏色作為後備,您可以執行下列操作。
In [222]: conditions = [
.....: (df['col2'] == 'Z') & (df['col1'] == 'A'),
.....: (df['col2'] == 'Z') & (df['col1'] == 'B'),
.....: (df['col1'] == 'B')
.....: ]
.....:
In [223]: choices = ['yellow', 'blue', 'purple']
In [224]: df['color'] = np.select(conditions, choices, default='black')
In [225]: df
Out[225]:
col1 col2 color
0 A Z yellow
1 B Z blue
2 B X purple
3 C Y black
方法 query()#
DataFrame 物件有一個 query() 方法,允許使用表達式進行選取。
你可以取得欄位 b 的值介於欄位 a 和 c 的值之間的 frame 值。例如
In [226]: n = 10
In [227]: df = pd.DataFrame(np.random.rand(n, 3), columns=list('abc'))
In [228]: df
Out[228]:
a b c
0 0.438921 0.118680 0.863670
1 0.138138 0.577363 0.686602
2 0.595307 0.564592 0.520630
3 0.913052 0.926075 0.616184
4 0.078718 0.854477 0.898725
5 0.076404 0.523211 0.591538
6 0.792342 0.216974 0.564056
7 0.397890 0.454131 0.915716
8 0.074315 0.437913 0.019794
9 0.559209 0.502065 0.026437
# pure python
In [229]: df[(df['a'] < df['b']) & (df['b'] < df['c'])]
Out[229]:
a b c
1 0.138138 0.577363 0.686602
4 0.078718 0.854477 0.898725
5 0.076404 0.523211 0.591538
7 0.397890 0.454131 0.915716
# query
In [230]: df.query('(a < b) & (b < c)')
Out[230]:
a b c
1 0.138138 0.577363 0.686602
4 0.078718 0.854477 0.898725
5 0.076404 0.523211 0.591538
7 0.397890 0.454131 0.915716
執行相同的動作,但如果沒有名稱為 a 的欄位,則回退到命名索引。
In [231]: df = pd.DataFrame(np.random.randint(n / 2, size=(n, 2)), columns=list('bc'))
In [232]: df.index.name = 'a'
In [233]: df
Out[233]:
b c
a
0 0 4
1 0 1
2 3 4
3 4 3
4 1 4
5 0 3
6 0 1
7 3 4
8 2 3
9 1 1
In [234]: df.query('a < b and b < c')
Out[234]:
b c
a
2 3 4
如果你不想或無法命名索引,你可以在查詢表達式中使用名稱 index
In [235]: df = pd.DataFrame(np.random.randint(n, size=(n, 2)), columns=list('bc'))
In [236]: df
Out[236]:
b c
0 3 1
1 3 0
2 5 6
3 5 2
4 7 4
5 0 1
6 2 5
7 0 1
8 6 0
9 7 9
In [237]: df.query('index < b < c')
Out[237]:
b c
2 5 6
注意
如果索引名稱與欄位名稱重疊,則優先考慮欄位名稱。例如,
In [238]: df = pd.DataFrame({'a': np.random.randint(5, size=5)})
In [239]: df.index.name = 'a'
In [240]: df.query('a > 2') # uses the column 'a', not the index
Out[240]:
a
a
1 3
3 3
你仍然可以使用特殊識別碼「index」在查詢表達式中使用索引
In [241]: df.query('index > 2')
Out[241]:
a
a
3 3
4 2
如果由於某些原因你有一個名為 index 的欄位,那麼你也可以將索引稱為 ilevel_0,但此時你應該考慮將欄位重新命名為較不含糊的名稱。
MultiIndex query() 語法#
您也可以將 DataFrame 的層級與 MultiIndex 搭配使用,就像它們是框中的欄位一樣
In [242]: n = 10
In [243]: colors = np.random.choice(['red', 'green'], size=n)
In [244]: foods = np.random.choice(['eggs', 'ham'], size=n)
In [245]: colors
Out[245]:
array(['red', 'red', 'red', 'green', 'green', 'green', 'green', 'green',
'green', 'green'], dtype='<U5')
In [246]: foods
Out[246]:
array(['ham', 'ham', 'eggs', 'eggs', 'eggs', 'ham', 'ham', 'eggs', 'eggs',
'eggs'], dtype='<U4')
In [247]: index = pd.MultiIndex.from_arrays([colors, foods], names=['color', 'food'])
In [248]: df = pd.DataFrame(np.random.randn(n, 2), index=index)
In [249]: df
Out[249]:
0 1
color food
red ham 0.194889 -0.381994
ham 0.318587 2.089075
eggs -0.728293 -0.090255
green eggs -0.748199 1.318931
eggs -2.029766 0.792652
ham 0.461007 -0.542749
ham -0.305384 -0.479195
eggs 0.095031 -0.270099
eggs -0.707140 -0.773882
eggs 0.229453 0.304418
In [250]: df.query('color == "red"')
Out[250]:
0 1
color food
red ham 0.194889 -0.381994
ham 0.318587 2.089075
eggs -0.728293 -0.090255
如果 MultiIndex 的層級未命名,您可以使用特殊名稱來參照它們
In [251]: df.index.names = [None, None]
In [252]: df
Out[252]:
0 1
red ham 0.194889 -0.381994
ham 0.318587 2.089075
eggs -0.728293 -0.090255
green eggs -0.748199 1.318931
eggs -2.029766 0.792652
ham 0.461007 -0.542749
ham -0.305384 -0.479195
eggs 0.095031 -0.270099
eggs -0.707140 -0.773882
eggs 0.229453 0.304418
In [253]: df.query('ilevel_0 == "red"')
Out[253]:
0 1
red ham 0.194889 -0.381994
ham 0.318587 2.089075
eggs -0.728293 -0.090255
慣例是 ilevel_0,表示 index 的第 0 個層級的「索引層級 0」
query() 使用案例#
query() 的一個使用案例是當您有一組 DataFrame 物件,它們具有子集的欄位名稱(或索引層級/名稱)共用。您可以將相同的查詢傳遞給兩個框,而不用指定您有興趣查詢哪個框
In [254]: df = pd.DataFrame(np.random.rand(n, 3), columns=list('abc'))
In [255]: df
Out[255]:
a b c
0 0.224283 0.736107 0.139168
1 0.302827 0.657803 0.713897
2 0.611185 0.136624 0.984960
3 0.195246 0.123436 0.627712
4 0.618673 0.371660 0.047902
5 0.480088 0.062993 0.185760
6 0.568018 0.483467 0.445289
7 0.309040 0.274580 0.587101
8 0.258993 0.477769 0.370255
9 0.550459 0.840870 0.304611
In [256]: df2 = pd.DataFrame(np.random.rand(n + 2, 3), columns=df.columns)
In [257]: df2
Out[257]:
a b c
0 0.357579 0.229800 0.596001
1 0.309059 0.957923 0.965663
2 0.123102 0.336914 0.318616
3 0.526506 0.323321 0.860813
4 0.518736 0.486514 0.384724
5 0.190804 0.505723 0.614533
6 0.891939 0.623977 0.676639
7 0.480559 0.378528 0.460858
8 0.420223 0.136404 0.141295
9 0.732206 0.419540 0.604675
10 0.604466 0.848974 0.896165
11 0.589168 0.920046 0.732716
In [258]: expr = '0.0 <= a <= c <= 0.5'
In [259]: map(lambda frame: frame.query(expr), [df, df2])
Out[259]: <map at 0x7fac68ab7580>
query() Python 與 pandas 語法比較#
完整的 numpy 式語法
In [260]: df = pd.DataFrame(np.random.randint(n, size=(n, 3)), columns=list('abc'))
In [261]: df
Out[261]:
a b c
0 7 8 9
1 1 0 7
2 2 7 2
3 6 2 2
4 2 6 3
5 3 8 2
6 1 7 2
7 5 1 5
8 9 8 0
9 1 5 0
In [262]: df.query('(a < b) & (b < c)')
Out[262]:
a b c
0 7 8 9
In [263]: df[(df['a'] < df['b']) & (df['b'] < df['c'])]
Out[263]:
a b c
0 7 8 9
移除括號後更簡潔(比較運算子比 & 和 | 的結合力更強)
In [264]: df.query('a < b & b < c')
Out[264]:
a b c
0 7 8 9
使用英文而非符號
In [265]: df.query('a < b and b < c')
Out[265]:
a b c
0 7 8 9
非常接近您在紙上撰寫的方式
In [266]: df.query('a < b < c')
Out[266]:
a b c
0 7 8 9
in 和 not in 運算子#
query() 也支援 Python 的 in 和 not in 比較運算子的特殊用法,提供簡潔的語法來呼叫 Series 或 DataFrame 的 isin 方法。
# get all rows where columns "a" and "b" have overlapping values
In [267]: df = pd.DataFrame({'a': list('aabbccddeeff'), 'b': list('aaaabbbbcccc'),
.....: 'c': np.random.randint(5, size=12),
.....: 'd': np.random.randint(9, size=12)})
.....:
In [268]: df
Out[268]:
a b c d
0 a a 2 6
1 a a 4 7
2 b a 1 6
3 b a 2 1
4 c b 3 6
5 c b 0 2
6 d b 3 3
7 d b 2 1
8 e c 4 3
9 e c 2 0
10 f c 0 6
11 f c 1 2
In [269]: df.query('a in b')
Out[269]:
a b c d
0 a a 2 6
1 a a 4 7
2 b a 1 6
3 b a 2 1
4 c b 3 6
5 c b 0 2
# How you'd do it in pure Python
In [270]: df[df['a'].isin(df['b'])]
Out[270]:
a b c d
0 a a 2 6
1 a a 4 7
2 b a 1 6
3 b a 2 1
4 c b 3 6
5 c b 0 2
In [271]: df.query('a not in b')
Out[271]:
a b c d
6 d b 3 3
7 d b 2 1
8 e c 4 3
9 e c 2 0
10 f c 0 6
11 f c 1 2
# pure Python
In [272]: df[~df['a'].isin(df['b'])]
Out[272]:
a b c d
6 d b 3 3
7 d b 2 1
8 e c 4 3
9 e c 2 0
10 f c 0 6
11 f c 1 2
您可以將這項功能與其他表達式結合,以進行非常簡潔的查詢
# rows where cols a and b have overlapping values
# and col c's values are less than col d's
In [273]: df.query('a in b and c < d')
Out[273]:
a b c d
0 a a 2 6
1 a a 4 7
2 b a 1 6
4 c b 3 6
5 c b 0 2
# pure Python
In [274]: df[df['b'].isin(df['a']) & (df['c'] < df['d'])]
Out[274]:
a b c d
0 a a 2 6
1 a a 4 7
2 b a 1 6
4 c b 3 6
5 c b 0 2
10 f c 0 6
11 f c 1 2
注意
請注意,in 和 not in 會在 Python 中評估,因為 numexpr 沒有這個運算式的等效項。不過,只有 in/not in 運算式本身 會在純 Python 中評估。例如,在運算式中
df.query('a in b + c + d')
(b + c + d) 由 numexpr 評估,然後 in 運算式會在純 Python 中評估。一般而言,任何可以使用 numexpr 評估的運算式都會使用。
使用 == 運算式搭配 list 物件的特殊用途#
使用 ==/!= 將 list 值與欄位進行比較,其運作方式類似於 in/not in。
In [275]: df.query('b == ["a", "b", "c"]')
Out[275]:
a b c d
0 a a 2 6
1 a a 4 7
2 b a 1 6
3 b a 2 1
4 c b 3 6
5 c b 0 2
6 d b 3 3
7 d b 2 1
8 e c 4 3
9 e c 2 0
10 f c 0 6
11 f c 1 2
# pure Python
In [276]: df[df['b'].isin(["a", "b", "c"])]
Out[276]:
a b c d
0 a a 2 6
1 a a 4 7
2 b a 1 6
3 b a 2 1
4 c b 3 6
5 c b 0 2
6 d b 3 3
7 d b 2 1
8 e c 4 3
9 e c 2 0
10 f c 0 6
11 f c 1 2
In [277]: df.query('c == [1, 2]')
Out[277]:
a b c d
0 a a 2 6
2 b a 1 6
3 b a 2 1
7 d b 2 1
9 e c 2 0
11 f c 1 2
In [278]: df.query('c != [1, 2]')
Out[278]:
a b c d
1 a a 4 7
4 c b 3 6
5 c b 0 2
6 d b 3 3
8 e c 4 3
10 f c 0 6
# using in/not in
In [279]: df.query('[1, 2] in c')
Out[279]:
a b c d
0 a a 2 6
2 b a 1 6
3 b a 2 1
7 d b 2 1
9 e c 2 0
11 f c 1 2
In [280]: df.query('[1, 2] not in c')
Out[280]:
a b c d
1 a a 4 7
4 c b 3 6
5 c b 0 2
6 d b 3 3
8 e c 4 3
10 f c 0 6
# pure Python
In [281]: df[df['c'].isin([1, 2])]
Out[281]:
a b c d
0 a a 2 6
2 b a 1 6
3 b a 2 1
7 d b 2 1
9 e c 2 0
11 f c 1 2
布林運算式#
您可以使用 not 字或 ~ 運算式來否定布林運算式。
In [282]: df = pd.DataFrame(np.random.rand(n, 3), columns=list('abc'))
In [283]: df['bools'] = np.random.rand(len(df)) > 0.5
In [284]: df.query('~bools')
Out[284]:
a b c bools
2 0.697753 0.212799 0.329209 False
7 0.275396 0.691034 0.826619 False
8 0.190649 0.558748 0.262467 False
In [285]: df.query('not bools')
Out[285]:
a b c bools
2 0.697753 0.212799 0.329209 False
7 0.275396 0.691034 0.826619 False
8 0.190649 0.558748 0.262467 False
In [286]: df.query('not bools') == df[~df['bools']]
Out[286]:
a b c bools
2 True True True True
7 True True True True
8 True True True True
當然,運算式也可以任意複雜
# short query syntax
In [287]: shorter = df.query('a < b < c and (not bools) or bools > 2')
# equivalent in pure Python
In [288]: longer = df[(df['a'] < df['b'])
.....: & (df['b'] < df['c'])
.....: & (~df['bools'])
.....: | (df['bools'] > 2)]
.....:
In [289]: shorter
Out[289]:
a b c bools
7 0.275396 0.691034 0.826619 False
In [290]: longer
Out[290]:
a b c bools
7 0.275396 0.691034 0.826619 False
In [291]: shorter == longer
Out[291]:
a b c bools
7 True True True True
query() 的效能#
DataFrame.query() 使用 numexpr 對於大型框架來說比 Python 稍微快一些。
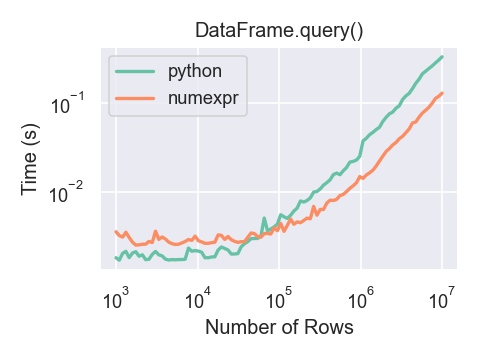
只有當你的框架有超過大約 100,000 列時,你才會看到使用 numexpr 引擎與 DataFrame.query() 的效能優勢。
這個圖表是使用 DataFrame 建立的,其中有 3 個欄位,每個欄位都包含使用 numpy.random.randn() 產生的浮點數值。
In [292]: df = pd.DataFrame(np.random.randn(8, 4),
.....: index=dates, columns=['A', 'B', 'C', 'D'])
.....:
In [293]: df2 = df.copy()
重複資料#
如果你想要識別並移除 DataFrame 中的重複列,有兩個方法可以幫助你:duplicated 和 drop_duplicates。每個方法都將用於識別重複列的欄位作為引數。
duplicated會傳回一個布林向量,其長度為列數,並指出列是否重複。drop_duplicates會移除重複列。
預設情況下,重複組的第一個觀察列會被視為唯一,但每個方法都有 keep 參數來指定要保留的目標。
keep='first'(預設):標記/移除重複項,但第一次出現的除外。keep='last':標記/移除重複項,但最後一次出現的除外。keep=False:標記/刪除所有重複項。
In [294]: df2 = pd.DataFrame({'a': ['one', 'one', 'two', 'two', 'two', 'three', 'four'],
.....: 'b': ['x', 'y', 'x', 'y', 'x', 'x', 'x'],
.....: 'c': np.random.randn(7)})
.....:
In [295]: df2
Out[295]:
a b c
0 one x -1.067137
1 one y 0.309500
2 two x -0.211056
3 two y -1.842023
4 two x -0.390820
5 three x -1.964475
6 four x 1.298329
In [296]: df2.duplicated('a')
Out[296]:
0 False
1 True
2 False
3 True
4 True
5 False
6 False
dtype: bool
In [297]: df2.duplicated('a', keep='last')
Out[297]:
0 True
1 False
2 True
3 True
4 False
5 False
6 False
dtype: bool
In [298]: df2.duplicated('a', keep=False)
Out[298]:
0 True
1 True
2 True
3 True
4 True
5 False
6 False
dtype: bool
In [299]: df2.drop_duplicates('a')
Out[299]:
a b c
0 one x -1.067137
2 two x -0.211056
5 three x -1.964475
6 four x 1.298329
In [300]: df2.drop_duplicates('a', keep='last')
Out[300]:
a b c
1 one y 0.309500
4 two x -0.390820
5 three x -1.964475
6 four x 1.298329
In [301]: df2.drop_duplicates('a', keep=False)
Out[301]:
a b c
5 three x -1.964475
6 four x 1.298329
此外,您可以傳遞一組欄位來識別重複項。
In [302]: df2.duplicated(['a', 'b'])
Out[302]:
0 False
1 False
2 False
3 False
4 True
5 False
6 False
dtype: bool
In [303]: df2.drop_duplicates(['a', 'b'])
Out[303]:
a b c
0 one x -1.067137
1 one y 0.309500
2 two x -0.211056
3 two y -1.842023
5 three x -1.964475
6 four x 1.298329
若要依索引值刪除重複項,請使用 Index.duplicated,然後執行切片。與 keep 參數可用的選項組相同。
In [304]: df3 = pd.DataFrame({'a': np.arange(6),
.....: 'b': np.random.randn(6)},
.....: index=['a', 'a', 'b', 'c', 'b', 'a'])
.....:
In [305]: df3
Out[305]:
a b
a 0 1.440455
a 1 2.456086
b 2 1.038402
c 3 -0.894409
b 4 0.683536
a 5 3.082764
In [306]: df3.index.duplicated()
Out[306]: array([False, True, False, False, True, True])
In [307]: df3[~df3.index.duplicated()]
Out[307]:
a b
a 0 1.440455
b 2 1.038402
c 3 -0.894409
In [308]: df3[~df3.index.duplicated(keep='last')]
Out[308]:
a b
c 3 -0.894409
b 4 0.683536
a 5 3.082764
In [309]: df3[~df3.index.duplicated(keep=False)]
Out[309]:
a b
c 3 -0.894409
類似字典的 get() 方法#
每個 Series 或 DataFrame 都有一個 get 方法,可傳回預設值。
In [310]: s = pd.Series([1, 2, 3], index=['a', 'b', 'c'])
In [311]: s.get('a') # equivalent to s['a']
Out[311]: 1
In [312]: s.get('x', default=-1)
Out[312]: -1
依索引/欄位標籤查詢值#
有時您會想要在給定一組列標籤和欄位標籤的情況下,擷取一組值,這可以使用 pandas.factorize 和 NumPy 編號來達成。例如
In [313]: df = pd.DataFrame({'col': ["A", "A", "B", "B"],
.....: 'A': [80, 23, np.nan, 22],
.....: 'B': [80, 55, 76, 67]})
.....:
In [314]: df
Out[314]:
col A B
0 A 80.0 80
1 A 23.0 55
2 B NaN 76
3 B 22.0 67
In [315]: idx, cols = pd.factorize(df['col'])
In [316]: df.reindex(cols, axis=1).to_numpy()[np.arange(len(df)), idx]
Out[316]: array([80., 23., 76., 67.])
以前可以使用專用的 DataFrame.lookup 方法來達成此目的,該方法已在版本 1.2.0 中標示為不建議使用,並在版本 2.0.0 中移除。
索引物件#
pandas Index 類別及其子類別可視為實作已排序的多重集合。允許重複項。
Index 也提供了查找、資料對齊和重新編製索引所需的基本架構。建立 Index 最簡單的方法是傳遞 list 或其他序列給 Index
In [317]: index = pd.Index(['e', 'd', 'a', 'b'])
In [318]: index
Out[318]: Index(['e', 'd', 'a', 'b'], dtype='object')
In [319]: 'd' in index
Out[319]: True
或使用數字
In [320]: index = pd.Index([1, 5, 12])
In [321]: index
Out[321]: Index([1, 5, 12], dtype='int64')
In [322]: 5 in index
Out[322]: True
如果沒有給定資料型態,Index 會嘗試從資料推斷資料型態。在建立 Index 時也可以給定明確的資料型態
In [323]: index = pd.Index(['e', 'd', 'a', 'b'], dtype="string")
In [324]: index
Out[324]: Index(['e', 'd', 'a', 'b'], dtype='string')
In [325]: index = pd.Index([1, 5, 12], dtype="int8")
In [326]: index
Out[326]: Index([1, 5, 12], dtype='int8')
In [327]: index = pd.Index([1, 5, 12], dtype="float32")
In [328]: index
Out[328]: Index([1.0, 5.0, 12.0], dtype='float32')
您也可以傳遞一個要儲存在索引中的 name
In [329]: index = pd.Index(['e', 'd', 'a', 'b'], name='something')
In [330]: index.name
Out[330]: 'something'
如果設定了名稱,會在主控台顯示中顯示該名稱
In [331]: index = pd.Index(list(range(5)), name='rows')
In [332]: columns = pd.Index(['A', 'B', 'C'], name='cols')
In [333]: df = pd.DataFrame(np.random.randn(5, 3), index=index, columns=columns)
In [334]: df
Out[334]:
cols A B C
rows
0 1.295989 -1.051694 1.340429
1 -2.366110 0.428241 0.387275
2 0.433306 0.929548 0.278094
3 2.154730 -0.315628 0.264223
4 1.126818 1.132290 -0.353310
In [335]: df['A']
Out[335]:
rows
0 1.295989
1 -2.366110
2 0.433306
3 2.154730
4 1.126818
Name: A, dtype: float64
設定元資料#
索引「幾乎是不可變的」,但可以設定和變更它們的 name 屬性。您可以使用 rename、set_names 直接設定這些屬性,它們預設會傳回一個副本。
請參閱 進階索引 以了解 MultiIndex 的用法。
In [336]: ind = pd.Index([1, 2, 3])
In [337]: ind.rename("apple")
Out[337]: Index([1, 2, 3], dtype='int64', name='apple')
In [338]: ind
Out[338]: Index([1, 2, 3], dtype='int64')
In [339]: ind = ind.set_names(["apple"])
In [340]: ind.name = "bob"
In [341]: ind
Out[341]: Index([1, 2, 3], dtype='int64', name='bob')
set_names、set_levels 和 set_codes 也會採用一個選用的 level 參數
In [342]: index = pd.MultiIndex.from_product([range(3), ['one', 'two']], names=['first', 'second'])
In [343]: index
Out[343]:
MultiIndex([(0, 'one'),
(0, 'two'),
(1, 'one'),
(1, 'two'),
(2, 'one'),
(2, 'two')],
names=['first', 'second'])
In [344]: index.levels[1]
Out[344]: Index(['one', 'two'], dtype='object', name='second')
In [345]: index.set_levels(["a", "b"], level=1)
Out[345]:
MultiIndex([(0, 'a'),
(0, 'b'),
(1, 'a'),
(1, 'b'),
(2, 'a'),
(2, 'b')],
names=['first', 'second'])
索引物件上的集合運算#
兩個主要的運算為 union 和 intersection。差異則透過 .difference() 方法提供。
In [346]: a = pd.Index(['c', 'b', 'a'])
In [347]: b = pd.Index(['c', 'e', 'd'])
In [348]: a.difference(b)
Out[348]: Index(['a', 'b'], dtype='object')
另外還有 symmetric_difference 運算,它會傳回出現在 idx1 或 idx2 中,但不出現在兩者中的元素。這等於由 idx1.difference(idx2).union(idx2.difference(idx1)) 建立的索引,且會移除重複值。
In [349]: idx1 = pd.Index([1, 2, 3, 4])
In [350]: idx2 = pd.Index([2, 3, 4, 5])
In [351]: idx1.symmetric_difference(idx2)
Out[351]: Index([1, 5], dtype='int64')
注意
集合運算所產生的索引結果會以遞增順序排序。
在具有不同資料類型的索引之間執行 Index.union() 時,必須將索引轉換為共用資料類型。通常,但並非總是,這會是物件資料類型。執行整數與浮點數資料之間的聯集時,則為例外。在這種情況下,整數值會轉換為浮點數
In [352]: idx1 = pd.Index([0, 1, 2])
In [353]: idx2 = pd.Index([0.5, 1.5])
In [354]: idx1.union(idx2)
Out[354]: Index([0.0, 0.5, 1.0, 1.5, 2.0], dtype='float64')
遺失值#
重要事項
即使 Index 可以保留遺失值 (NaN),如果您不想要任何意外結果,則應避免使用。例如,有些運算會隱含排除遺失值。
Index.fillna 會以指定的純量值填入遺失值。
In [355]: idx1 = pd.Index([1, np.nan, 3, 4])
In [356]: idx1
Out[356]: Index([1.0, nan, 3.0, 4.0], dtype='float64')
In [357]: idx1.fillna(2)
Out[357]: Index([1.0, 2.0, 3.0, 4.0], dtype='float64')
In [358]: idx2 = pd.DatetimeIndex([pd.Timestamp('2011-01-01'),
.....: pd.NaT,
.....: pd.Timestamp('2011-01-03')])
.....:
In [359]: idx2
Out[359]: DatetimeIndex(['2011-01-01', 'NaT', '2011-01-03'], dtype='datetime64[ns]', freq=None)
In [360]: idx2.fillna(pd.Timestamp('2011-01-02'))
Out[360]: DatetimeIndex(['2011-01-01', '2011-01-02', '2011-01-03'], dtype='datetime64[ns]', freq=None)
設定/重設索引#
偶爾您會將資料集載入或建立至資料框中,並希望在完成後新增索引。有幾種不同的方法。
設定索引#
DataFrame 有 set_index() 方法,它採用欄位名稱(針對一般 Index)或欄位名稱清單(針對 MultiIndex)。若要建立新的重新編製索引的 DataFrame
In [361]: data = pd.DataFrame({'a': ['bar', 'bar', 'foo', 'foo'],
.....: 'b': ['one', 'two', 'one', 'two'],
.....: 'c': ['z', 'y', 'x', 'w'],
.....: 'd': [1., 2., 3, 4]})
.....:
In [362]: data
Out[362]:
a b c d
0 bar one z 1.0
1 bar two y 2.0
2 foo one x 3.0
3 foo two w 4.0
In [363]: indexed1 = data.set_index('c')
In [364]: indexed1
Out[364]:
a b d
c
z bar one 1.0
y bar two 2.0
x foo one 3.0
w foo two 4.0
In [365]: indexed2 = data.set_index(['a', 'b'])
In [366]: indexed2
Out[366]:
c d
a b
bar one z 1.0
two y 2.0
foo one x 3.0
two w 4.0
append 關鍵字選項讓您可以保留現有索引,並將給定的欄位附加到 MultiIndex
In [367]: frame = data.set_index('c', drop=False)
In [368]: frame = frame.set_index(['a', 'b'], append=True)
In [369]: frame
Out[369]:
c d
c a b
z bar one z 1.0
y bar two y 2.0
x foo one x 3.0
w foo two w 4.0
set_index 中的其他選項讓您不刪除索引欄位。
In [370]: data.set_index('c', drop=False)
Out[370]:
a b c d
c
z bar one z 1.0
y bar two y 2.0
x foo one x 3.0
w foo two w 4.0
重設索引#
為方便起見,DataFrame 上有一個稱為 reset_index() 的新函式,它會將索引值傳輸到 DataFrame 的欄位中,並設定一個簡單的整數索引。這是 set_index() 的反向操作。
In [371]: data
Out[371]:
a b c d
0 bar one z 1.0
1 bar two y 2.0
2 foo one x 3.0
3 foo two w 4.0
In [372]: data.reset_index()
Out[372]:
index a b c d
0 0 bar one z 1.0
1 1 bar two y 2.0
2 2 foo one x 3.0
3 3 foo two w 4.0
輸出更類似於 SQL 表格或記錄陣列。從索引衍生的欄位名稱是儲存在 names 屬性中的名稱。
您可以使用 level 關鍵字僅移除索引的一部分
In [373]: frame
Out[373]:
c d
c a b
z bar one z 1.0
y bar two y 2.0
x foo one x 3.0
w foo two w 4.0
In [374]: frame.reset_index(level=1)
Out[374]:
a c d
c b
z one bar z 1.0
y two bar y 2.0
x one foo x 3.0
w two foo w 4.0
reset_index 採用一個選用參數 drop,如果為 true 則僅捨棄索引,而非將索引值放入 DataFrame 的欄位中。
新增臨時索引#
您可以將自訂索引指定給 index 屬性
In [375]: df_idx = pd.DataFrame(range(4))
In [376]: df_idx.index = pd.Index([10, 20, 30, 40], name="a")
In [377]: df_idx
Out[377]:
0
a
10 0
20 1
30 2
40 3
傳回檢視而非副本#
警告
寫入時複製 將成為 pandas 3.0 的新預設值。這表示連鎖索引將永遠無法運作。因此,SettingWithCopyWarning 將不再必要。請參閱 此區段 以取得更多背景資訊。我們建議開啟寫入時複製,以透過下列方式提升效能
` pd.options.mode.copy_on_write = True `
甚至在 pandas 3.0 推出之前。
在 pandas 物件中設定值時,必須小心避免所謂的 連鎖 索引。以下是一個範例。
In [378]: dfmi = pd.DataFrame([list('abcd'),
.....: list('efgh'),
.....: list('ijkl'),
.....: list('mnop')],
.....: columns=pd.MultiIndex.from_product([['one', 'two'],
.....: ['first', 'second']]))
.....:
In [379]: dfmi
Out[379]:
one two
first second first second
0 a b c d
1 e f g h
2 i j k l
3 m n o p
比較這兩種存取方法
In [380]: dfmi['one']['second']
Out[380]:
0 b
1 f
2 j
3 n
Name: second, dtype: object
In [381]: dfmi.loc[:, ('one', 'second')]
Out[381]:
0 b
1 f
2 j
3 n
Name: (one, second), dtype: object
這兩種方法都會產生相同的結果,因此您應該使用哪一種?了解這些方法的運算順序以及為何方法 2 (.loc) 遠比方法 1 (連鎖 []) 優先,是有幫助的。
dfmi['one'] 選取欄位的第 1 層級,並傳回單一索引的 DataFrame。然後另一個 Python 操作 dfmi_with_one['second'] 選取由 'second' 索引的系列。這由變數 dfmi_with_one 指出,因為 pandas 視這些操作為個別事件。例如,個別呼叫 __getitem__,因此必須將它們視為線性操作,它們會一個接一個發生。
將此與 df.loc[:,('one','second')] 相比,它將 (slice(None),('one','second')) 的巢狀 tuple 傳遞給 __getitem__ 的單一呼叫。這允許 pandas 將此視為單一實體。此外,這種運算順序可以顯著加快速度,並允許在需要時索引兩個軸。
使用鏈式索引時,為何指派會失敗?#
警告
寫入時複製 將成為 pandas 3.0 的新預設值。這表示連鎖索引將永遠無法運作。因此,SettingWithCopyWarning 將不再必要。請參閱 此區段 以取得更多背景資訊。我們建議開啟寫入時複製,以透過下列方式提升效能
` pd.options.mode.copy_on_write = True `
甚至在 pandas 3.0 推出之前。
前一節的問題只是一個效能問題。SettingWithCopy 警告又是怎麼回事?當您執行可能花費額外幾毫秒時間的事情時,我們通常不會發出警告!
但事實證明,指派給鏈式索引的乘積會產生本質上無法預測的結果。要了解這一點,請思考 Python 解譯器如何執行這段程式碼
dfmi.loc[:, ('one', 'second')] = value
# becomes
dfmi.loc.__setitem__((slice(None), ('one', 'second')), value)
但這段程式碼的處理方式不同
dfmi['one']['second'] = value
# becomes
dfmi.__getitem__('one').__setitem__('second', value)
看到那邊的 __getitem__ 嗎?在非單純的情況下,很難預測它會傳回檢視或拷貝(這取決於陣列的記憶體配置,而 pandas 並未對此提供保證),因此 __setitem__ 會修改 dfmi 或一個隨後立即拋棄的暫時物件。這就是 SettingWithCopy 警告你的內容!
注意
你可能會想,我們是否應該擔心第一個範例中的 loc 屬性。但 dfmi.loc 保證是 dfmi 本身,具有修改的索引行為,因此 dfmi.loc.__getitem__ / dfmi.loc.__setitem__ 直接在 dfmi 上運作。當然,dfmi.loc.__getitem__(idx) 可能會是 dfmi 的檢視或拷貝。
有時,在沒有明顯的連鎖索引進行時,也會出現 SettingWithCopy 警告。這些就是 SettingWithCopy 設計來偵測的錯誤!pandas 可能試著警告你,你已經這樣做了
def do_something(df):
foo = df[['bar', 'baz']] # Is foo a view? A copy? Nobody knows!
# ... many lines here ...
# We don't know whether this will modify df or not!
foo['quux'] = value
return foo
哎呀!
評估順序很重要#
警告
寫入時複製 將成為 pandas 3.0 的新預設值。這表示連鎖索引將永遠無法運作。因此,SettingWithCopyWarning 將不再必要。請參閱 此區段 以取得更多背景資訊。我們建議開啟寫入時複製,以透過下列方式提升效能
` pd.options.mode.copy_on_write = True `
甚至在 pandas 3.0 推出之前。
當你使用連鎖索引時,索引操作的順序和類型會部分決定結果是原始物件的區段,還是區段的拷貝。
pandas 有 SettingWithCopyWarning,因為指派到切片的拷貝通常不是故意的,而是由鏈結索引傳回拷貝(預期是切片)所造成的錯誤。
如果您希望 pandas 對鏈結索引表達式的指派更加或不太信任,您可以將 選項 mode.chained_assignment 設定為下列其中一個值
'warn',預設值,表示會印出SettingWithCopyWarning。'raise'表示 pandas 會引發SettingWithCopyError,您必須處理。None將完全抑制警告。
In [382]: dfb = pd.DataFrame({'a': ['one', 'one', 'two',
.....: 'three', 'two', 'one', 'six'],
.....: 'c': np.arange(7)})
.....:
# This will show the SettingWithCopyWarning
# but the frame values will be set
In [383]: dfb['c'][dfb['a'].str.startswith('o')] = 42
不過,這是對拷貝進行操作,而且不會運作。
In [384]: with pd.option_context('mode.chained_assignment','warn'):
.....: dfb[dfb['a'].str.startswith('o')]['c'] = 42
.....:
鏈結指派也可能發生在混合資料型別的框架設定中。
注意
這些設定規則適用於所有 .loc/.iloc。
以下是使用 .loc 的建議存取方法,用於多個項目(使用 mask)和使用固定索引的單一項目
In [385]: dfc = pd.DataFrame({'a': ['one', 'one', 'two',
.....: 'three', 'two', 'one', 'six'],
.....: 'c': np.arange(7)})
.....:
In [386]: dfd = dfc.copy()
# Setting multiple items using a mask
In [387]: mask = dfd['a'].str.startswith('o')
In [388]: dfd.loc[mask, 'c'] = 42
In [389]: dfd
Out[389]:
a c
0 one 42
1 one 42
2 two 2
3 three 3
4 two 4
5 one 42
6 six 6
# Setting a single item
In [390]: dfd = dfc.copy()
In [391]: dfd.loc[2, 'a'] = 11
In [392]: dfd
Out[392]:
a c
0 one 0
1 one 1
2 11 2
3 three 3
4 two 4
5 one 5
6 six 6
以下內容有時可以運作,但並非保證,因此應避免使用
In [393]: dfd = dfc.copy()
In [394]: dfd['a'][2] = 111
In [395]: dfd
Out[395]:
a c
0 one 0
1 one 1
2 111 2
3 three 3
4 two 4
5 one 5
6 six 6
最後,後續範例將完全無法運作,因此應避免使用
In [396]: with pd.option_context('mode.chained_assignment','raise'):
.....: dfd.loc[0]['a'] = 1111
.....:
---------------------------------------------------------------------------
SettingWithCopyError Traceback (most recent call last)
<ipython-input-396-32ce785aaa5b> in ?()
1 with pd.option_context('mode.chained_assignment','raise'):
----> 2 dfd.loc[0]['a'] = 1111
~/work/pandas/pandas/pandas/core/series.py in ?(self, key, value)
1275 )
1276
1277 check_dict_or_set_indexers(key)
1278 key = com.apply_if_callable(key, self)
-> 1279 cacher_needs_updating = self._check_is_chained_assignment_possible()
1280
1281 if key is Ellipsis:
1282 key = slice(None)
~/work/pandas/pandas/pandas/core/series.py in ?(self)
1480 ref = self._get_cacher()
1481 if ref is not None and ref._is_mixed_type:
1482 self._check_setitem_copy(t="referent", force=True)
1483 return True
-> 1484 return super()._check_is_chained_assignment_possible()
~/work/pandas/pandas/pandas/core/generic.py in ?(self)
4392 single-dtype meaning that the cacher should be updated following
4393 setting.
4394 """
4395 if self._is_copy:
-> 4396 self._check_setitem_copy(t="referent")
4397 return False
~/work/pandas/pandas/pandas/core/generic.py in ?(self, t, force)
4466 "indexing.html#returning-a-view-versus-a-copy"
4467 )
4468
4469 if value == "raise":
-> 4470 raise SettingWithCopyError(t)
4471 if value == "warn":
4472 warnings.warn(t, SettingWithCopyWarning, stacklevel=find_stack_level())
SettingWithCopyError:
A value is trying to be set on a copy of a slice from a DataFrame
See the caveats in the documentation: https://pandas.dev.org.tw/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
警告
鏈結指派警告/例外旨在告知使用者可能有無效的指派。可能會出現誤報;意外報告鏈結指派的情況。