合併、聯結、串接和比較#
pandas 提供各種方法來組合和比較 Series 或 DataFrame。
DataFrame.join():合併多個DataFrame物件,並沿著欄位DataFrame.combine_first():使用相同位置的非遺失值來更新遺失值merge_ordered():沿著順序軸結合兩個Series或DataFrame物件merge_asof():透過近似而非完全匹配的鍵,結合兩個Series或DataFrame物件Series.compare()和DataFrame.compare():顯示兩個Series或DataFrame物件之間的數值差異
concat()#
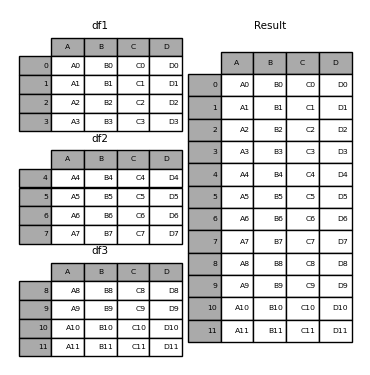
concat() 函數會沿著軸串接任意數量的 Series 或 DataFrame 物件,同時對其他軸上的索引執行選用設定邏輯(聯集或交集)。像 numpy.concatenate 一樣,concat() 會取得均質類型物件的清單或字典,並將它們串接起來。
In [1]: df1 = pd.DataFrame(
...: {
...: "A": ["A0", "A1", "A2", "A3"],
...: "B": ["B0", "B1", "B2", "B3"],
...: "C": ["C0", "C1", "C2", "C3"],
...: "D": ["D0", "D1", "D2", "D3"],
...: },
...: index=[0, 1, 2, 3],
...: )
...:
In [2]: df2 = pd.DataFrame(
...: {
...: "A": ["A4", "A5", "A6", "A7"],
...: "B": ["B4", "B5", "B6", "B7"],
...: "C": ["C4", "C5", "C6", "C7"],
...: "D": ["D4", "D5", "D6", "D7"],
...: },
...: index=[4, 5, 6, 7],
...: )
...:
In [3]: df3 = pd.DataFrame(
...: {
...: "A": ["A8", "A9", "A10", "A11"],
...: "B": ["B8", "B9", "B10", "B11"],
...: "C": ["C8", "C9", "C10", "C11"],
...: "D": ["D8", "D9", "D10", "D11"],
...: },
...: index=[8, 9, 10, 11],
...: )
...:
In [4]: frames = [df1, df2, df3]
In [5]: result = pd.concat(frames)
In [6]: result
Out[6]:
A B C D
0 A0 B0 C0 D0
1 A1 B1 C1 D1
2 A2 B2 C2 D2
3 A3 B3 C3 D3
4 A4 B4 C4 D4
5 A5 B5 C5 D5
6 A6 B6 C6 D6
7 A7 B7 C7 D7
8 A8 B8 C8 D8
9 A9 B9 C9 D9
10 A10 B10 C10 D10
11 A11 B11 C11 D11
注意
concat() 會建立資料的完整副本,而反覆使用 concat() 可能會建立不必要的副本。在使用 concat() 之前,請先將所有 DataFrame 或 Series 物件收集到清單中。
frames = [process_your_file(f) for f in files]
result = pd.concat(frames)
注意
當串接具有命名軸的 DataFrame 時,pandas 會盡可能嘗試保留這些索引/欄位名稱。如果所有輸入共用一個共通名稱,此名稱會指派給結果。如果輸入名稱不同,結果會是未命名。對 MultiIndex 來說也是一樣,但邏輯會逐層個別套用。
結果軸的合併邏輯#
關鍵字 join 指定如何處理第一個 DataFrame 中不存在的軸值。
join='outer' 取所有軸值的聯集
In [7]: df4 = pd.DataFrame(
...: {
...: "B": ["B2", "B3", "B6", "B7"],
...: "D": ["D2", "D3", "D6", "D7"],
...: "F": ["F2", "F3", "F6", "F7"],
...: },
...: index=[2, 3, 6, 7],
...: )
...:
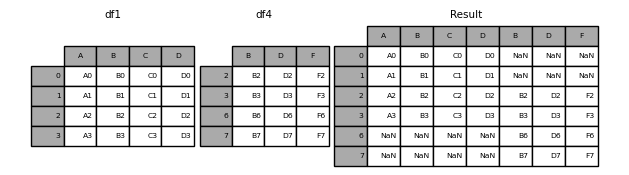
In [8]: result = pd.concat([df1, df4], axis=1)
In [9]: result
Out[9]:
A B C D B D F
0 A0 B0 C0 D0 NaN NaN NaN
1 A1 B1 C1 D1 NaN NaN NaN
2 A2 B2 C2 D2 B2 D2 F2
3 A3 B3 C3 D3 B3 D3 F3
6 NaN NaN NaN NaN B6 D6 F6
7 NaN NaN NaN NaN B7 D7 F7
join='inner' 取軸值的交集
In [10]: result = pd.concat([df1, df4], axis=1, join="inner")
In [11]: result
Out[11]:
A B C D B D F
2 A2 B2 C2 D2 B2 D2 F2
3 A3 B3 C3 D3 B3 D3 F3

若要使用原始 DataFrame 的精確索引執行有效的「左」聯結,結果可以重新索引。
In [12]: result = pd.concat([df1, df4], axis=1).reindex(df1.index)
In [13]: result
Out[13]:
A B C D B D F
0 A0 B0 C0 D0 NaN NaN NaN
1 A1 B1 C1 D1 NaN NaN NaN
2 A2 B2 C2 D2 B2 D2 F2
3 A3 B3 C3 D3 B3 D3 F3

忽略串接軸上的索引#
對於沒有有意義索引的 DataFrame 物件,ignore_index 會忽略重疊的索引。
In [14]: result = pd.concat([df1, df4], ignore_index=True, sort=False)
In [15]: result
Out[15]:
A B C D F
0 A0 B0 C0 D0 NaN
1 A1 B1 C1 D1 NaN
2 A2 B2 C2 D2 NaN
3 A3 B3 C3 D3 NaN
4 NaN B2 NaN D2 F2
5 NaN B3 NaN D3 F3
6 NaN B6 NaN D6 F6
7 NaN B7 NaN D7 F7

串接 Series 和 DataFrame #
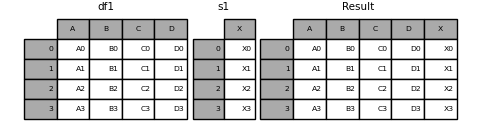
您可以串接 Series 和 DataFrame 物件的組合。 Series 會轉換成 DataFrame,其中欄位名稱為 Series 的名稱。
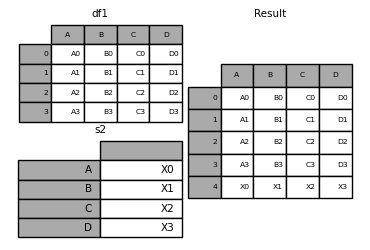
In [16]: s1 = pd.Series(["X0", "X1", "X2", "X3"], name="X")
In [17]: result = pd.concat([df1, s1], axis=1)
In [18]: result
Out[18]:
A B C D X
0 A0 B0 C0 D0 X0
1 A1 B1 C1 D1 X1
2 A2 B2 C2 D2 X2
3 A3 B3 C3 D3 X3
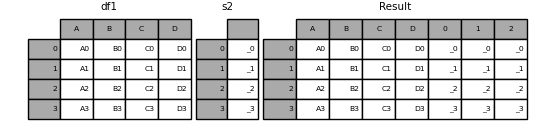
未命名的 Series 會連續編號。
In [19]: s2 = pd.Series(["_0", "_1", "_2", "_3"])
In [20]: result = pd.concat([df1, s2, s2, s2], axis=1)
In [21]: result
Out[21]:
A B C D 0 1 2
0 A0 B0 C0 D0 _0 _0 _0
1 A1 B1 C1 D1 _1 _1 _1
2 A2 B2 C2 D2 _2 _2 _2
3 A3 B3 C3 D3 _3 _3 _3
ignore_index=True 會捨棄所有名稱參照。
In [22]: result = pd.concat([df1, s1], axis=1, ignore_index=True)
In [23]: result
Out[23]:
0 1 2 3 4
0 A0 B0 C0 D0 X0
1 A1 B1 C1 D1 X1
2 A2 B2 C2 D2 X2
3 A3 B3 C3 D3 X3
產生的 keys#
keys 參數會在產生的索引或欄位中新增另一個軸向層級(建立 MultiIndex),將特定金鑰與每個原始 DataFrame 關聯起來。
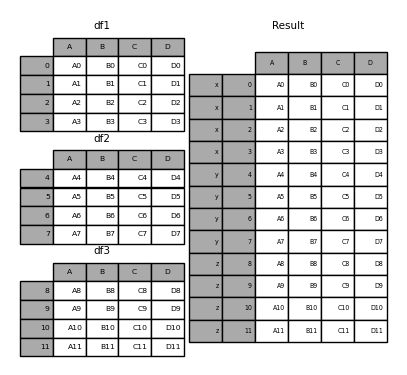
In [24]: result = pd.concat(frames, keys=["x", "y", "z"])
In [25]: result
Out[25]:
A B C D
x 0 A0 B0 C0 D0
1 A1 B1 C1 D1
2 A2 B2 C2 D2
3 A3 B3 C3 D3
y 4 A4 B4 C4 D4
5 A5 B5 C5 D5
6 A6 B6 C6 D6
7 A7 B7 C7 D7
z 8 A8 B8 C8 D8
9 A9 B9 C9 D9
10 A10 B10 C10 D10
11 A11 B11 C11 D11
In [26]: result.loc["y"]
Out[26]:
A B C D
4 A4 B4 C4 D4
5 A5 B5 C5 D5
6 A6 B6 C6 D6
7 A7 B7 C7 D7
當建立一個新的 DataFrame 基於現有的 Series 時,keys 參數可以覆寫欄位名稱。
In [27]: s3 = pd.Series([0, 1, 2, 3], name="foo")
In [28]: s4 = pd.Series([0, 1, 2, 3])
In [29]: s5 = pd.Series([0, 1, 4, 5])
In [30]: pd.concat([s3, s4, s5], axis=1)
Out[30]:
foo 0 1
0 0 0 0
1 1 1 1
2 2 2 4
3 3 3 5
In [31]: pd.concat([s3, s4, s5], axis=1, keys=["red", "blue", "yellow"])
Out[31]:
red blue yellow
0 0 0 0
1 1 1 1
2 2 2 4
3 3 3 5
您也可以傳遞一個字典給 concat(),這種情況下,字典的鍵值將會用於 keys 參數,除非有其他 keys 參數被指定。
In [32]: pieces = {"x": df1, "y": df2, "z": df3}
In [33]: result = pd.concat(pieces)
In [34]: result
Out[34]:
A B C D
x 0 A0 B0 C0 D0
1 A1 B1 C1 D1
2 A2 B2 C2 D2
3 A3 B3 C3 D3
y 4 A4 B4 C4 D4
5 A5 B5 C5 D5
6 A6 B6 C6 D6
7 A7 B7 C7 D7
z 8 A8 B8 C8 D8
9 A9 B9 C9 D9
10 A10 B10 C10 D10
11 A11 B11 C11 D11
In [35]: result = pd.concat(pieces, keys=["z", "y"])
In [36]: result
Out[36]:
A B C D
z 8 A8 B8 C8 D8
9 A9 B9 C9 D9
10 A10 B10 C10 D10
11 A11 B11 C11 D11
y 4 A4 B4 C4 D4
5 A5 B5 C5 D5
6 A6 B6 C6 D6
7 A7 B7 C7 D7
所建立的 MultiIndex 有層級,這些層級是由傳遞的鍵值和 DataFrame 片段的索引所建立的。
In [37]: result.index.levels
Out[37]: FrozenList([['z', 'y'], [4, 5, 6, 7, 8, 9, 10, 11]])
levels 參數允許指定與 keys 相關的結果層級。
In [38]: result = pd.concat(
....: pieces, keys=["x", "y", "z"], levels=[["z", "y", "x", "w"]], names=["group_key"]
....: )
....:
In [39]: result
Out[39]:
A B C D
group_key
x 0 A0 B0 C0 D0
1 A1 B1 C1 D1
2 A2 B2 C2 D2
3 A3 B3 C3 D3
y 4 A4 B4 C4 D4
5 A5 B5 C5 D5
6 A6 B6 C6 D6
7 A7 B7 C7 D7
z 8 A8 B8 C8 D8
9 A9 B9 C9 D9
10 A10 B10 C10 D10
11 A11 B11 C11 D11
In [40]: result.index.levels
Out[40]: FrozenList([['z', 'y', 'x', 'w'], [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]])
附加列到 DataFrame#
如果您有一個 Series,您想要將其作為單一列附加到 DataFrame,您可以將該列轉換為 DataFrame 並使用 concat()
In [41]: s2 = pd.Series(["X0", "X1", "X2", "X3"], index=["A", "B", "C", "D"])
In [42]: result = pd.concat([df1, s2.to_frame().T], ignore_index=True)
In [43]: result
Out[43]:
A B C D
0 A0 B0 C0 D0
1 A1 B1 C1 D1
2 A2 B2 C2 D2
3 A3 B3 C3 D3
4 X0 X1 X2 X3
merge()#
merge() 執行類似於 SQL 等關聯式資料庫的聯結操作。熟悉 SQL 但不熟悉 pandas 的使用者可以參考 與 SQL 的比較。
合併類型#
merge() 實作常見的 SQL 風格聯結操作。
注意
在將欄位與欄位結合時,可能會產生多對多結合,已傳遞 DataFrame 物件上的任何索引都會被捨棄。
對於多對多結合,如果在兩個表格中某個金鑰組合出現超過一次,DataFrame 將會產生關聯資料的笛卡兒積。
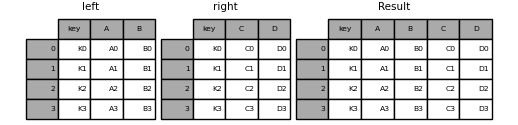
In [44]: left = pd.DataFrame(
....: {
....: "key": ["K0", "K1", "K2", "K3"],
....: "A": ["A0", "A1", "A2", "A3"],
....: "B": ["B0", "B1", "B2", "B3"],
....: }
....: )
....:
In [45]: right = pd.DataFrame(
....: {
....: "key": ["K0", "K1", "K2", "K3"],
....: "C": ["C0", "C1", "C2", "C3"],
....: "D": ["D0", "D1", "D2", "D3"],
....: }
....: )
....:
In [46]: result = pd.merge(left, right, on="key")
In [47]: result
Out[47]:
key A B C D
0 K0 A0 B0 C0 D0
1 K1 A1 B1 C1 D1
2 K2 A2 B2 C2 D2
3 K3 A3 B3 C3 D3
傳遞給 merge() 的 how 參數會指定結果表格中包含哪些金鑰。如果金鑰組合未出現在左邊或右邊的表格中,合併表格中的值將會是 NA。以下是 how 選項及其等效 SQL 名稱的摘要
合併方法 |
SQL Join 名稱 |
說明 |
|---|---|---|
|
|
僅使用左邊框架的金鑰 |
|
|
僅使用右邊框架的金鑰 |
|
|
使用兩個框架中金鑰的聯集 |
|
|
使用兩個框架中金鑰的交集 |
|
|
建立兩個框架中列的笛卡兒積 |
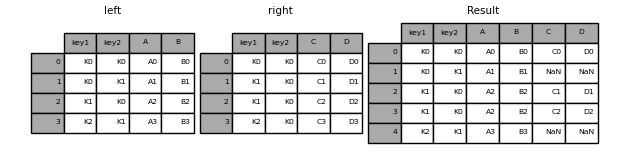
In [48]: left = pd.DataFrame(
....: {
....: "key1": ["K0", "K0", "K1", "K2"],
....: "key2": ["K0", "K1", "K0", "K1"],
....: "A": ["A0", "A1", "A2", "A3"],
....: "B": ["B0", "B1", "B2", "B3"],
....: }
....: )
....:
In [49]: right = pd.DataFrame(
....: {
....: "key1": ["K0", "K1", "K1", "K2"],
....: "key2": ["K0", "K0", "K0", "K0"],
....: "C": ["C0", "C1", "C2", "C3"],
....: "D": ["D0", "D1", "D2", "D3"],
....: }
....: )
....:
In [50]: result = pd.merge(left, right, how="left", on=["key1", "key2"])
In [51]: result
Out[51]:
key1 key2 A B C D
0 K0 K0 A0 B0 C0 D0
1 K0 K1 A1 B1 NaN NaN
2 K1 K0 A2 B2 C1 D1
3 K1 K0 A2 B2 C2 D2
4 K2 K1 A3 B3 NaN NaN
In [52]: result = pd.merge(left, right, how="right", on=["key1", "key2"])
In [53]: result
Out[53]:
key1 key2 A B C D
0 K0 K0 A0 B0 C0 D0
1 K1 K0 A2 B2 C1 D1
2 K1 K0 A2 B2 C2 D2
3 K2 K0 NaN NaN C3 D3

In [54]: result = pd.merge(left, right, how="outer", on=["key1", "key2"])
In [55]: result
Out[55]:
key1 key2 A B C D
0 K0 K0 A0 B0 C0 D0
1 K0 K1 A1 B1 NaN NaN
2 K1 K0 A2 B2 C1 D1
3 K1 K0 A2 B2 C2 D2
4 K2 K0 NaN NaN C3 D3
5 K2 K1 A3 B3 NaN NaN
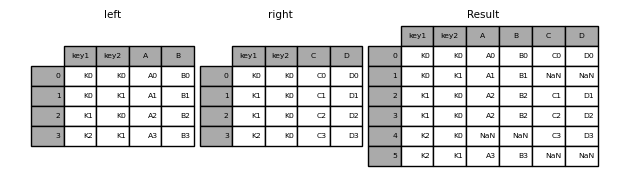
In [56]: result = pd.merge(left, right, how="inner", on=["key1", "key2"])
In [57]: result
Out[57]:
key1 key2 A B C D
0 K0 K0 A0 B0 C0 D0
1 K1 K0 A2 B2 C1 D1
2 K1 K0 A2 B2 C2 D2

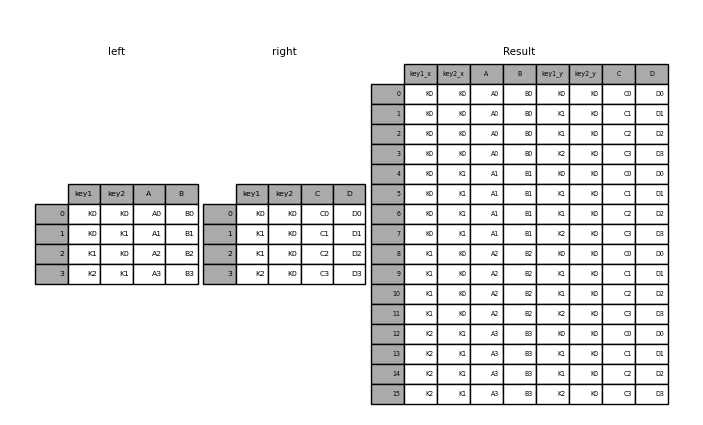
In [58]: result = pd.merge(left, right, how="cross")
In [59]: result
Out[59]:
key1_x key2_x A B key1_y key2_y C D
0 K0 K0 A0 B0 K0 K0 C0 D0
1 K0 K0 A0 B0 K1 K0 C1 D1
2 K0 K0 A0 B0 K1 K0 C2 D2
3 K0 K0 A0 B0 K2 K0 C3 D3
4 K0 K1 A1 B1 K0 K0 C0 D0
.. ... ... .. .. ... ... .. ..
11 K1 K0 A2 B2 K2 K0 C3 D3
12 K2 K1 A3 B3 K0 K0 C0 D0
13 K2 K1 A3 B3 K1 K0 C1 D1
14 K2 K1 A3 B3 K1 K0 C2 D2
15 K2 K1 A3 B3 K2 K0 C3 D3
[16 rows x 8 columns]
如果 Series 和 DataFrame 的名稱與 MultiIndex 的欄位相符,則可以使用 MultiIndex。在合併之前,使用 Series.reset_index() 將 Series 轉換為 DataFrame。
In [60]: df = pd.DataFrame({"Let": ["A", "B", "C"], "Num": [1, 2, 3]})
In [61]: df
Out[61]:
Let Num
0 A 1
1 B 2
2 C 3
In [62]: ser = pd.Series(
....: ["a", "b", "c", "d", "e", "f"],
....: index=pd.MultiIndex.from_arrays(
....: [["A", "B", "C"] * 2, [1, 2, 3, 4, 5, 6]], names=["Let", "Num"]
....: ),
....: )
....:
In [63]: ser
Out[63]:
Let Num
A 1 a
B 2 b
C 3 c
A 4 d
B 5 e
C 6 f
dtype: object
In [64]: pd.merge(df, ser.reset_index(), on=["Let", "Num"])
Out[64]:
Let Num 0
0 A 1 a
1 B 2 b
2 C 3 c
在 DataFrame 中使用重複的合併鍵執行外部合併
In [65]: left = pd.DataFrame({"A": [1, 2], "B": [2, 2]})
In [66]: right = pd.DataFrame({"A": [4, 5, 6], "B": [2, 2, 2]})
In [67]: result = pd.merge(left, right, on="B", how="outer")
In [68]: result
Out[68]:
A_x B A_y
0 1 2 4
1 1 2 5
2 1 2 6
3 2 2 4
4 2 2 5
5 2 2 6
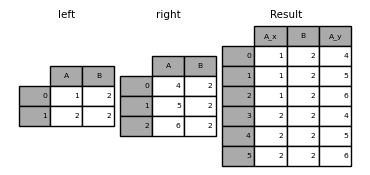
警告
在重複的鍵上合併會大幅增加結果的維度,並可能導致記憶體溢位。
合併鍵的唯一性#
validate 參數會檢查合併鍵的唯一性。在合併作業之前會檢查鍵的唯一性,並可以防止記憶體溢位和意外的鍵重複。
In [69]: left = pd.DataFrame({"A": [1, 2], "B": [1, 2]})
In [70]: right = pd.DataFrame({"A": [4, 5, 6], "B": [2, 2, 2]})
In [71]: result = pd.merge(left, right, on="B", how="outer", validate="one_to_one")
---------------------------------------------------------------------------
MergeError Traceback (most recent call last)
Cell In[71], line 1
----> 1 result = pd.merge(left, right, on="B", how="outer", validate="one_to_one")
File ~/work/pandas/pandas/pandas/core/reshape/merge.py:170, in merge(left, right, how, on, left_on, right_on, left_index, right_index, sort, suffixes, copy, indicator, validate)
155 return _cross_merge(
156 left_df,
157 right_df,
(...)
167 copy=copy,
168 )
169 else:
--> 170 op = _MergeOperation(
171 left_df,
172 right_df,
173 how=how,
174 on=on,
175 left_on=left_on,
176 right_on=right_on,
177 left_index=left_index,
178 right_index=right_index,
179 sort=sort,
180 suffixes=suffixes,
181 indicator=indicator,
182 validate=validate,
183 )
184 return op.get_result(copy=copy)
File ~/work/pandas/pandas/pandas/core/reshape/merge.py:813, in _MergeOperation.__init__(self, left, right, how, on, left_on, right_on, left_index, right_index, sort, suffixes, indicator, validate)
809 # If argument passed to validate,
810 # check if columns specified as unique
811 # are in fact unique.
812 if validate is not None:
--> 813 self._validate_validate_kwd(validate)
File ~/work/pandas/pandas/pandas/core/reshape/merge.py:1657, in _MergeOperation._validate_validate_kwd(self, validate)
1653 raise MergeError(
1654 "Merge keys are not unique in left dataset; not a one-to-one merge"
1655 )
1656 if not right_unique:
-> 1657 raise MergeError(
1658 "Merge keys are not unique in right dataset; not a one-to-one merge"
1659 )
1661 elif validate in ["one_to_many", "1:m"]:
1662 if not left_unique:
MergeError: Merge keys are not unique in right dataset; not a one-to-one merge
如果使用者知道右邊的 DataFrame 有重複的資料,但想要確保左邊的 DataFrame 沒有重複的資料,可以使用 validate='one_to_many' 參數,這樣就不會引發例外。
In [72]: pd.merge(left, right, on="B", how="outer", validate="one_to_many")
Out[72]:
A_x B A_y
0 1 1 NaN
1 2 2 4.0
2 2 2 5.0
3 2 2 6.0
合併結果指標#
merge() 接受 indicator 參數。如果為 True,會在輸出物件中新增一個稱為 _merge 的類別型欄位,其值如下:
觀察來源
_merge值合併鍵只在
'left'框架中
left_only合併鍵只在
'right'框架中
right_only合併鍵在兩個框架中
both
In [73]: df1 = pd.DataFrame({"col1": [0, 1], "col_left": ["a", "b"]})
In [74]: df2 = pd.DataFrame({"col1": [1, 2, 2], "col_right": [2, 2, 2]})
In [75]: pd.merge(df1, df2, on="col1", how="outer", indicator=True)
Out[75]:
col1 col_left col_right _merge
0 0 a NaN left_only
1 1 b 2.0 both
2 2 NaN 2.0 right_only
3 2 NaN 2.0 right_only
傳遞字串參數給 indicator 會將該值用作指標欄位的名稱。
In [76]: pd.merge(df1, df2, on="col1", how="outer", indicator="indicator_column")
Out[76]:
col1 col_left col_right indicator_column
0 0 a NaN left_only
1 1 b 2.0 both
2 2 NaN 2.0 right_only
3 2 NaN 2.0 right_only
重疊的值欄位#
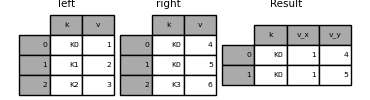
合併 suffixes 參數會取得一個字串清單的元組,以附加到輸入 DataFrame 中重疊的欄位名稱,以區分結果欄位
In [77]: left = pd.DataFrame({"k": ["K0", "K1", "K2"], "v": [1, 2, 3]})
In [78]: right = pd.DataFrame({"k": ["K0", "K0", "K3"], "v": [4, 5, 6]})
In [79]: result = pd.merge(left, right, on="k")
In [80]: result
Out[80]:
k v_x v_y
0 K0 1 4
1 K0 1 5
In [81]: result = pd.merge(left, right, on="k", suffixes=("_l", "_r"))
In [82]: result
Out[82]:
k v_l v_r
0 K0 1 4
1 K0 1 5
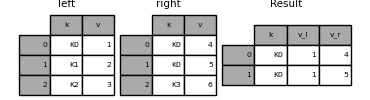
DataFrame.join()#
DataFrame.join() 結合多個可能索引不同的 DataFrame 欄位,成為單一結果 DataFrame。
In [83]: left = pd.DataFrame(
....: {"A": ["A0", "A1", "A2"], "B": ["B0", "B1", "B2"]}, index=["K0", "K1", "K2"]
....: )
....:
In [84]: right = pd.DataFrame(
....: {"C": ["C0", "C2", "C3"], "D": ["D0", "D2", "D3"]}, index=["K0", "K2", "K3"]
....: )
....:
In [85]: result = left.join(right)
In [86]: result
Out[86]:
A B C D
K0 A0 B0 C0 D0
K1 A1 B1 NaN NaN
K2 A2 B2 C2 D2
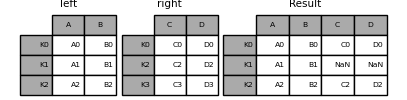
In [87]: result = left.join(right, how="outer")
In [88]: result
Out[88]:
A B C D
K0 A0 B0 C0 D0
K1 A1 B1 NaN NaN
K2 A2 B2 C2 D2
K3 NaN NaN C3 D3
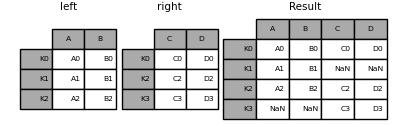
In [89]: result = left.join(right, how="inner")
In [90]: result
Out[90]:
A B C D
K0 A0 B0 C0 D0
K2 A2 B2 C2 D2
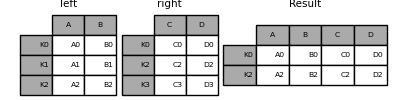
DataFrame.join() 接受一個選用的 on 參數,它可能是欄位或多個欄位名稱,用於對齊傳遞的 DataFrame。
In [91]: left = pd.DataFrame(
....: {
....: "A": ["A0", "A1", "A2", "A3"],
....: "B": ["B0", "B1", "B2", "B3"],
....: "key": ["K0", "K1", "K0", "K1"],
....: }
....: )
....:
In [92]: right = pd.DataFrame({"C": ["C0", "C1"], "D": ["D0", "D1"]}, index=["K0", "K1"])
In [93]: result = left.join(right, on="key")
In [94]: result
Out[94]:
A B key C D
0 A0 B0 K0 C0 D0
1 A1 B1 K1 C1 D1
2 A2 B2 K0 C0 D0
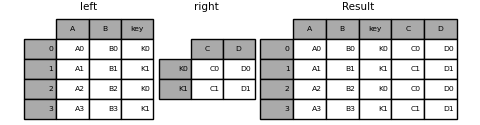
3 A3 B3 K1 C1 D1
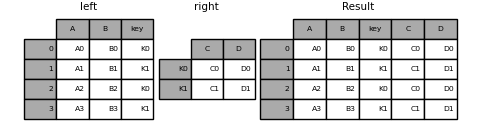
In [95]: result = pd.merge(
....: left, right, left_on="key", right_index=True, how="left", sort=False
....: )
....:
In [96]: result
Out[96]:
A B key C D
0 A0 B0 K0 C0 D0
1 A1 B1 K1 C1 D1
2 A2 B2 K0 C0 D0
3 A3 B3 K1 C1 D1
若要根據多個鍵進行合併,傳遞的 DataFrame 必須具有 MultiIndex。
In [97]: left = pd.DataFrame(
....: {
....: "A": ["A0", "A1", "A2", "A3"],
....: "B": ["B0", "B1", "B2", "B3"],
....: "key1": ["K0", "K0", "K1", "K2"],
....: "key2": ["K0", "K1", "K0", "K1"],
....: }
....: )
....:
In [98]: index = pd.MultiIndex.from_tuples(
....: [("K0", "K0"), ("K1", "K0"), ("K2", "K0"), ("K2", "K1")]
....: )
....:
In [99]: right = pd.DataFrame(
....: {"C": ["C0", "C1", "C2", "C3"], "D": ["D0", "D1", "D2", "D3"]}, index=index
....: )
....:
In [100]: result = left.join(right, on=["key1", "key2"])
In [101]: result
Out[101]:
A B key1 key2 C D
0 A0 B0 K0 K0 C0 D0
1 A1 B1 K0 K1 NaN NaN
2 A2 B2 K1 K0 C1 D1
3 A3 B3 K2 K1 C3 D3
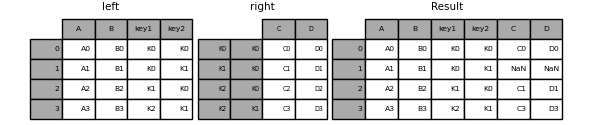
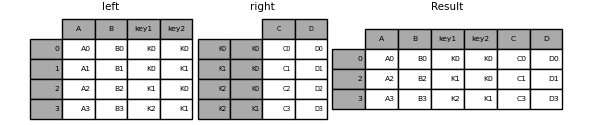
預設的 DataFrame.join 會執行左聯結,只使用呼叫 DataFrame 中找到的鍵。其他聯結類型可以用 how 指定。
In [102]: result = left.join(right, on=["key1", "key2"], how="inner")
In [103]: result
Out[103]:
A B key1 key2 C D
0 A0 B0 K0 K0 C0 D0
2 A2 B2 K1 K0 C1 D1
3 A3 B3 K2 K1 C3 D3
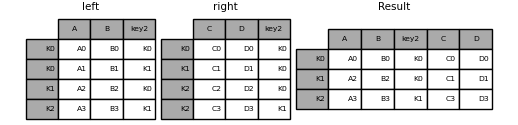
將單一索引聯結到多重索引#
你可以將一個 DataFrame 與 Index 加入到一個 DataFrame 中,其中包含一個 MultiIndex。 Index 的 name 會與 MultiIndex 的層級名稱相符。
In [104]: left = pd.DataFrame(
.....: {"A": ["A0", "A1", "A2"], "B": ["B0", "B1", "B2"]},
.....: index=pd.Index(["K0", "K1", "K2"], name="key"),
.....: )
.....:
In [105]: index = pd.MultiIndex.from_tuples(
.....: [("K0", "Y0"), ("K1", "Y1"), ("K2", "Y2"), ("K2", "Y3")],
.....: names=["key", "Y"],
.....: )
.....:
In [106]: right = pd.DataFrame(
.....: {"C": ["C0", "C1", "C2", "C3"], "D": ["D0", "D1", "D2", "D3"]},
.....: index=index,
.....: )
.....:
In [107]: result = left.join(right, how="inner")
In [108]: result
Out[108]:
A B C D
key Y
K0 Y0 A0 B0 C0 D0
K1 Y1 A1 B1 C1 D1
K2 Y2 A2 B2 C2 D2
Y3 A2 B2 C3 D3
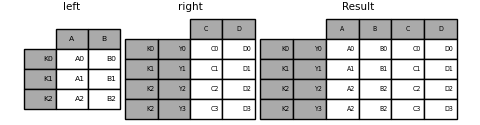
使用兩個 MultiIndex 進行合併#
輸入參數的 MultiIndex 必須完全用於合併,並且是左參數中索引的子集。
In [109]: leftindex = pd.MultiIndex.from_product(
.....: [list("abc"), list("xy"), [1, 2]], names=["abc", "xy", "num"]
.....: )
.....:
In [110]: left = pd.DataFrame({"v1": range(12)}, index=leftindex)
In [111]: left
Out[111]:
v1
abc xy num
a x 1 0
2 1
y 1 2
2 3
b x 1 4
2 5
y 1 6
2 7
c x 1 8
2 9
y 1 10
2 11
In [112]: rightindex = pd.MultiIndex.from_product(
.....: [list("abc"), list("xy")], names=["abc", "xy"]
.....: )
.....:
In [113]: right = pd.DataFrame({"v2": [100 * i for i in range(1, 7)]}, index=rightindex)
In [114]: right
Out[114]:
v2
abc xy
a x 100
y 200
b x 300
y 400
c x 500
y 600
In [115]: left.join(right, on=["abc", "xy"], how="inner")
Out[115]:
v1 v2
abc xy num
a x 1 0 100
2 1 100
y 1 2 200
2 3 200
b x 1 4 300
2 5 300
y 1 6 400
2 7 400
c x 1 8 500
2 9 500
y 1 10 600
2 11 600
In [116]: leftindex = pd.MultiIndex.from_tuples(
.....: [("K0", "X0"), ("K0", "X1"), ("K1", "X2")], names=["key", "X"]
.....: )
.....:
In [117]: left = pd.DataFrame(
.....: {"A": ["A0", "A1", "A2"], "B": ["B0", "B1", "B2"]}, index=leftindex
.....: )
.....:
In [118]: rightindex = pd.MultiIndex.from_tuples(
.....: [("K0", "Y0"), ("K1", "Y1"), ("K2", "Y2"), ("K2", "Y3")], names=["key", "Y"]
.....: )
.....:
In [119]: right = pd.DataFrame(
.....: {"C": ["C0", "C1", "C2", "C3"], "D": ["D0", "D1", "D2", "D3"]}, index=rightindex
.....: )
.....:
In [120]: result = pd.merge(
.....: left.reset_index(), right.reset_index(), on=["key"], how="inner"
.....: ).set_index(["key", "X", "Y"])
.....:
In [121]: result
Out[121]:
A B C D
key X Y
K0 X0 Y0 A0 B0 C0 D0
X1 Y0 A1 B1 C0 D0
K1 X2 Y1 A2 B2 C1 D1
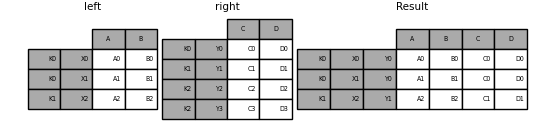
合併欄位和索引層級的組合#
傳遞為 on、left_on 和 right_on 參數的字串可以參照欄位名稱或索引層級名稱。這允許合併 DataFrame 執行個體,並結合索引層級和欄位,而無需重設索引。
In [122]: left_index = pd.Index(["K0", "K0", "K1", "K2"], name="key1")
In [123]: left = pd.DataFrame(
.....: {
.....: "A": ["A0", "A1", "A2", "A3"],
.....: "B": ["B0", "B1", "B2", "B3"],
.....: "key2": ["K0", "K1", "K0", "K1"],
.....: },
.....: index=left_index,
.....: )
.....:
In [124]: right_index = pd.Index(["K0", "K1", "K2", "K2"], name="key1")
In [125]: right = pd.DataFrame(
.....: {
.....: "C": ["C0", "C1", "C2", "C3"],
.....: "D": ["D0", "D1", "D2", "D3"],
.....: "key2": ["K0", "K0", "K0", "K1"],
.....: },
.....: index=right_index,
.....: )
.....:
In [126]: result = left.merge(right, on=["key1", "key2"])
In [127]: result
Out[127]:
A B key2 C D
key1
K0 A0 B0 K0 C0 D0
K1 A2 B2 K0 C1 D1
K2 A3 B3 K1 C3 D3
注意
當 DataFrame 僅使用 MultiIndex 的部分層級來連接時,額外的層級將從結果連接中刪除。若要保留這些層級,請在這些層級名稱上使用 DataFrame.reset_index(),以便在連接之前將這些層級移至欄位。
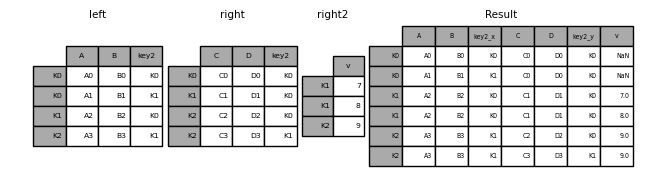
連接多個 DataFrame#
:class:`DataFrame` 的清單或元組也可以傳遞給 join(),以在索引上將它們連接在一起。
In [128]: right2 = pd.DataFrame({"v": [7, 8, 9]}, index=["K1", "K1", "K2"])
In [129]: result = left.join([right, right2])
DataFrame.combine_first()#
DataFrame.combine_first() 使用另一個 DataFrame 中的非遺失值更新一個 DataFrame 中的遺失值,位置相對應。
In [130]: df1 = pd.DataFrame(
.....: [[np.nan, 3.0, 5.0], [-4.6, np.nan, np.nan], [np.nan, 7.0, np.nan]]
.....: )
.....:
In [131]: df2 = pd.DataFrame([[-42.6, np.nan, -8.2], [-5.0, 1.6, 4]], index=[1, 2])
In [132]: result = df1.combine_first(df2)
In [133]: result
Out[133]:
0 1 2
0 NaN 3.0 5.0
1 -4.6 NaN -8.2
2 -5.0 7.0 4.0
merge_ordered()#
merge_ordered() 結合順序資料,例如數字或時間序列資料,並可選擇使用 fill_method 填入遺失的資料。
In [134]: left = pd.DataFrame(
.....: {"k": ["K0", "K1", "K1", "K2"], "lv": [1, 2, 3, 4], "s": ["a", "b", "c", "d"]}
.....: )
.....:
In [135]: right = pd.DataFrame({"k": ["K1", "K2", "K4"], "rv": [1, 2, 3]})
In [136]: pd.merge_ordered(left, right, fill_method="ffill", left_by="s")
Out[136]:
k lv s rv
0 K0 1.0 a NaN
1 K1 1.0 a 1.0
2 K2 1.0 a 2.0
3 K4 1.0 a 3.0
4 K1 2.0 b 1.0
5 K2 2.0 b 2.0
6 K4 2.0 b 3.0
7 K1 3.0 c 1.0
8 K2 3.0 c 2.0
9 K4 3.0 c 3.0
10 K1 NaN d 1.0
11 K2 4.0 d 2.0
12 K4 4.0 d 3.0
merge_asof()#
merge_asof() 類似於排序的左連接,但配對是根據最近的鍵,而不是等於的鍵。對於 left DataFrame 中的每一列,right DataFrame 中的最後一列會在 on 鍵小於左側鍵的情況下選取。兩個 DataFrame 都必須根據鍵排序。
選擇性地,merge_asof() 可以透過配對 by 鍵,除了在 on 鍵上進行最近配對之外,執行群組合併。
In [137]: trades = pd.DataFrame(
.....: {
.....: "time": pd.to_datetime(
.....: [
.....: "20160525 13:30:00.023",
.....: "20160525 13:30:00.038",
.....: "20160525 13:30:00.048",
.....: "20160525 13:30:00.048",
.....: "20160525 13:30:00.048",
.....: ]
.....: ),
.....: "ticker": ["MSFT", "MSFT", "GOOG", "GOOG", "AAPL"],
.....: "price": [51.95, 51.95, 720.77, 720.92, 98.00],
.....: "quantity": [75, 155, 100, 100, 100],
.....: },
.....: columns=["time", "ticker", "price", "quantity"],
.....: )
.....:
In [138]: quotes = pd.DataFrame(
.....: {
.....: "time": pd.to_datetime(
.....: [
.....: "20160525 13:30:00.023",
.....: "20160525 13:30:00.023",
.....: "20160525 13:30:00.030",
.....: "20160525 13:30:00.041",
.....: "20160525 13:30:00.048",
.....: "20160525 13:30:00.049",
.....: "20160525 13:30:00.072",
.....: "20160525 13:30:00.075",
.....: ]
.....: ),
.....: "ticker": ["GOOG", "MSFT", "MSFT", "MSFT", "GOOG", "AAPL", "GOOG", "MSFT"],
.....: "bid": [720.50, 51.95, 51.97, 51.99, 720.50, 97.99, 720.50, 52.01],
.....: "ask": [720.93, 51.96, 51.98, 52.00, 720.93, 98.01, 720.88, 52.03],
.....: },
.....: columns=["time", "ticker", "bid", "ask"],
.....: )
.....:
In [139]: trades
Out[139]:
time ticker price quantity
0 2016-05-25 13:30:00.023 MSFT 51.95 75
1 2016-05-25 13:30:00.038 MSFT 51.95 155
2 2016-05-25 13:30:00.048 GOOG 720.77 100
3 2016-05-25 13:30:00.048 GOOG 720.92 100
4 2016-05-25 13:30:00.048 AAPL 98.00 100
In [140]: quotes
Out[140]:
time ticker bid ask
0 2016-05-25 13:30:00.023 GOOG 720.50 720.93
1 2016-05-25 13:30:00.023 MSFT 51.95 51.96
2 2016-05-25 13:30:00.030 MSFT 51.97 51.98
3 2016-05-25 13:30:00.041 MSFT 51.99 52.00
4 2016-05-25 13:30:00.048 GOOG 720.50 720.93
5 2016-05-25 13:30:00.049 AAPL 97.99 98.01
6 2016-05-25 13:30:00.072 GOOG 720.50 720.88
7 2016-05-25 13:30:00.075 MSFT 52.01 52.03
In [141]: pd.merge_asof(trades, quotes, on="time", by="ticker")
Out[141]:
time ticker price quantity bid ask
0 2016-05-25 13:30:00.023 MSFT 51.95 75 51.95 51.96
1 2016-05-25 13:30:00.038 MSFT 51.95 155 51.97 51.98
2 2016-05-25 13:30:00.048 GOOG 720.77 100 720.50 720.93
3 2016-05-25 13:30:00.048 GOOG 720.92 100 720.50 720.93
4 2016-05-25 13:30:00.048 AAPL 98.00 100 NaN NaN
merge_asof() 在報價時間和交易時間之間 2ms 內。
In [142]: pd.merge_asof(trades, quotes, on="time", by="ticker", tolerance=pd.Timedelta("2ms"))
Out[142]:
time ticker price quantity bid ask
0 2016-05-25 13:30:00.023 MSFT 51.95 75 51.95 51.96
1 2016-05-25 13:30:00.038 MSFT 51.95 155 NaN NaN
2 2016-05-25 13:30:00.048 GOOG 720.77 100 720.50 720.93
3 2016-05-25 13:30:00.048 GOOG 720.92 100 720.50 720.93
4 2016-05-25 13:30:00.048 AAPL 98.00 100 NaN NaN
merge_asof() 在報價時間與交易時間之間10ms內,並排除時間上完全相符的資料。請注意,雖然我們排除了完全相符的資料(報價),但之前的報價會傳播到那個時間點。
In [143]: pd.merge_asof(
.....: trades,
.....: quotes,
.....: on="time",
.....: by="ticker",
.....: tolerance=pd.Timedelta("10ms"),
.....: allow_exact_matches=False,
.....: )
.....:
Out[143]:
time ticker price quantity bid ask
0 2016-05-25 13:30:00.023 MSFT 51.95 75 NaN NaN
1 2016-05-25 13:30:00.038 MSFT 51.95 155 51.97 51.98
2 2016-05-25 13:30:00.048 GOOG 720.77 100 NaN NaN
3 2016-05-25 13:30:00.048 GOOG 720.92 100 NaN NaN
4 2016-05-25 13:30:00.048 AAPL 98.00 100 NaN NaN
compare()#
Series.compare() 和 DataFrame.compare() 方法允許您比較兩個 DataFrame 或 Series,並摘要它們的差異。
In [144]: df = pd.DataFrame(
.....: {
.....: "col1": ["a", "a", "b", "b", "a"],
.....: "col2": [1.0, 2.0, 3.0, np.nan, 5.0],
.....: "col3": [1.0, 2.0, 3.0, 4.0, 5.0],
.....: },
.....: columns=["col1", "col2", "col3"],
.....: )
.....:
In [145]: df
Out[145]:
col1 col2 col3
0 a 1.0 1.0
1 a 2.0 2.0
2 b 3.0 3.0
3 b NaN 4.0
4 a 5.0 5.0
In [146]: df2 = df.copy()
In [147]: df2.loc[0, "col1"] = "c"
In [148]: df2.loc[2, "col3"] = 4.0
In [149]: df2
Out[149]:
col1 col2 col3
0 c 1.0 1.0
1 a 2.0 2.0
2 b 3.0 4.0
3 b NaN 4.0
4 a 5.0 5.0
In [150]: df.compare(df2)
Out[150]:
col1 col3
self other self other
0 a c NaN NaN
2 NaN NaN 3.0 4.0
預設情況下,如果兩個對應的值相等,它們將顯示為 NaN。此外,如果整行/整欄中的所有值,則結果中將省略該行/欄。其餘差異將在欄位上對齊。
將差異堆疊在列上。
In [151]: df.compare(df2, align_axis=0)
Out[151]:
col1 col3
0 self a NaN
other c NaN
2 self NaN 3.0
other NaN 4.0
使用 keep_shape=True 保留所有原始列和行
In [152]: df.compare(df2, keep_shape=True)
Out[152]:
col1 col2 col3
self other self other self other
0 a c NaN NaN NaN NaN
1 NaN NaN NaN NaN NaN NaN
2 NaN NaN NaN NaN 3.0 4.0
3 NaN NaN NaN NaN NaN NaN
4 NaN NaN NaN NaN NaN NaN
即使值相等,也要保留所有原始值。
In [153]: df.compare(df2, keep_shape=True, keep_equal=True)
Out[153]:
col1 col2 col3
self other self other self other
0 a c 1.0 1.0 1.0 1.0
1 a a 2.0 2.0 2.0 2.0
2 b b 3.0 3.0 3.0 4.0
3 b b NaN NaN 4.0 4.0
4 a a 5.0 5.0 5.0 5.0