生態系
越來越多套件建立在 pandas 之上,以滿足資料準備、分析和視覺化的特定需求。這令人振奮,因為這表示 pandas 不僅協助使用者處理其資料任務,還為開發人員提供更好的起點,以建立功能強大且更專注的資料工具。建立與 pandas 功能互補的函式庫,也能讓 pandas 的開發持續專注於其原始需求。
這是由社群維護的專案清單,這些專案建立在 pandas 之上,以在 PyData 領域中提供工具。pandas 核心開發團隊不一定認可此清單中的任何特定專案,或對任何特定函式庫的維護狀態有任何了解。
如需依賴 pandas 的專案的更完整清單,請參閱 libraries.io pandas 使用頁面 或 在 pypi 中搜尋 pandas。
我們希望讓使用者更容易找到這些專案,如果您知道其他您認為應該在此清單上的重要專案,請讓我們知道。
統計和機器學習
Statsmodels
Statsmodels 是著名的 Python「統計和計量經濟學程式庫」,並且與 pandas 有長期的特殊關係。Statsmodels 提供強大的統計、計量經濟學、分析和建模功能,這些功能不在 pandas 的範圍內。Statsmodels 使用 pandas 物件作為運算的底層資料容器。
Featuretools
Featuretools 是建立在 pandas 之上的 Python 自動特徵工程程式庫。它擅長使用可重複使用的特徵工程「基本元素」將時間和關係資料集轉換成機器學習的特徵矩陣。使用者可以在 Python 中貢獻自己的基本元素,並與社群的其他成員分享。
Compose
Compose 是用於標記資料和預測工程的機器學習工具。它允許您透過參數化預測問題和將時間驅動的關係資料轉換成目標值(可使用於監督式學習)來建構標記流程,這些目標值具有可用的截止時間。
STUMPY
STUMPY 是用於現代時間序列分析的強大且可擴充的 Python 程式庫。STUMPY 的核心是有效地計算稱為矩陣特徵的東西,可使用於各種時間序列資料探勘任務。
視覺化
Altair
Altair 是 Python 的宣告式統計視覺化程式庫。使用 Altair,您可以花更多時間了解您的資料及其意義。Altair 的 API 簡單、友善且一致,並建立在強大的 Vega-Lite JSON 規格之上。這種優雅的簡潔性可使用最少的程式碼產生美觀且有效的視覺化。Altair 可搭配 Pandas 資料框使用。
Bokeh
Bokeh 是一個 Python 互動式視覺化函式庫,適用於原生使用最新網路技術的大型資料集。其目標是提供優雅、簡潔的 Protovis/D3 風格新穎圖形建構,同時提供大型資料在精簡客戶端上的高效能互動性。
Pandas-Bokeh 提供 Bokeh 的高階 API,可透過以下方式載入為原生 Pandas 繪圖後端
pd.set_option("plotting.backend", "pandas_bokeh")
它與 matplotlib 繪圖後端非常類似,但提供互動式網路圖表和地圖。
pygwalker
PyGWalker 是一個互動式資料視覺化和探索性資料分析工具,建構在 Graphic Walker 上,支援視覺化、清理和註解工作流程。
pygwalker 可以將互動式建立的圖表儲存到 Graphic-Walker 和 Vega-Lite JSON。
import pygwalker as pyg
pyg.walk(df)
seaborn
Seaborn 是基於 matplotlib 的 Python 視覺化函式庫。它提供一個高階、以資料集為導向的介面,用於建立有吸引力的統計圖形。Seaborn 中的繪圖函數了解 pandas 物件,並在內部利用 pandas 分組運算,以支援複雜視覺化的簡潔規格。Seaborn 還超越了 matplotlib 和 pandas,提供在繪圖時執行統計估計、跨觀察聚合和視覺化統計模型的擬合,以強調資料集中的模式。
import seaborn as sns
sns.set_theme()
plotnine
Hadley Wickham 的 ggplot2 是 R 語言的基本探索性視覺化套件。它基於 "The Grammar of Graphics",提供一種強大、宣告式且極為通用的方式,用於產生任何類型資料的客製化圖形。有各種實作可供其他語言使用。對於 Python 使用者而言,一個好的實作是 has2k1/plotnine。
IPython Vega
IPython Vega 利用 Vega 在 Jupyter Notebook 中建立圖表。
Plotly
Plotly 的 Python API 能夠產生互動式圖形並能在網路上分享。地圖、2D、3D 和串流圖形都是使用 WebGL 和 D3.js 繪製的。這個函式庫支援直接從 pandas DataFrame 繪製圖形,並支援雲端協作。matplotlib、ggplot for Python 和 Seaborn 的使用者可以將圖形轉換成互動式的網路圖形。圖形可以在 IPython Notebooks 中繪製,並使用 R 或 MATLAB 編輯,在 GUI 中修改,或嵌入在應用程式和儀表板中。Plotly 可以免費無限分享,並有 雲端、離線 或 內部部署 帳戶供私人使用。
Lux
Lux 是 Python 函式庫,透過自動化視覺化資料探索流程,協助快速且輕鬆地進行資料實驗。要使用 Lux,只要在 pandas 旁邊新增額外的 import
import lux
import pandas as pd
df = pd.read_csv("data.csv")
df # discover interesting insights!
透過列印出資料框,Lux 會自動 建議一組視覺化,以突顯資料框中有趣的趨勢和模式。使用者可以利用任何現有的 pandas 指令,而不用修改他們的程式碼,同時還能視覺化他們的 pandas 資料結構(例如,DataFrame、Series、Index)。Lux 還提供 強大且直覺的語言,讓使用者可以建立 Altair、matplotlib 或 Vega-Lite 視覺化,而不用在程式碼層級思考。
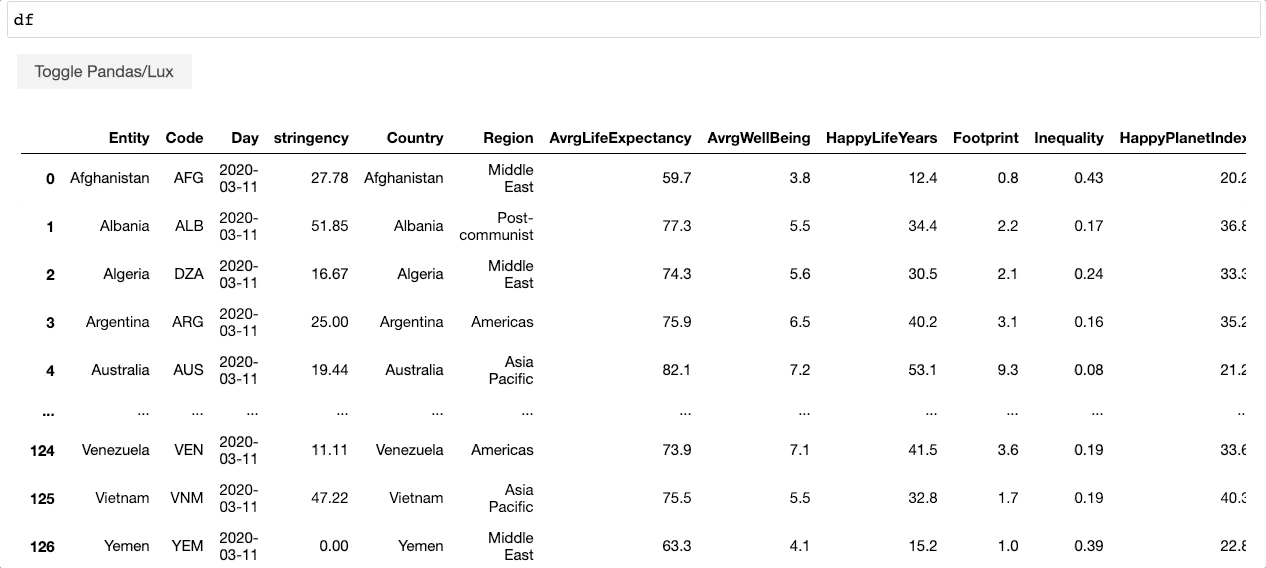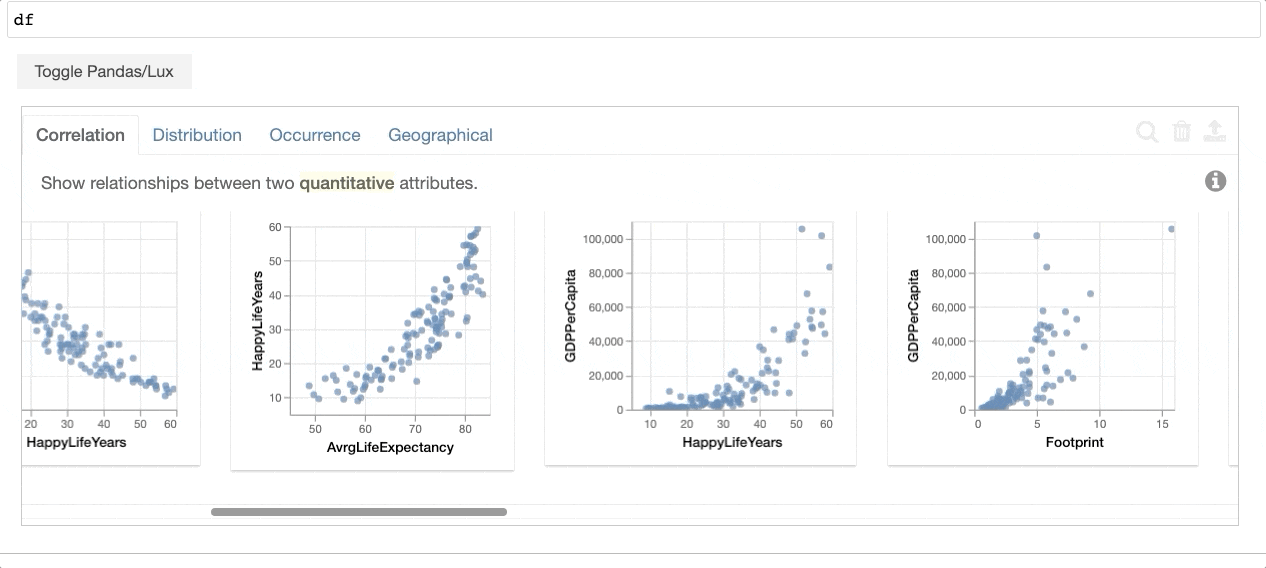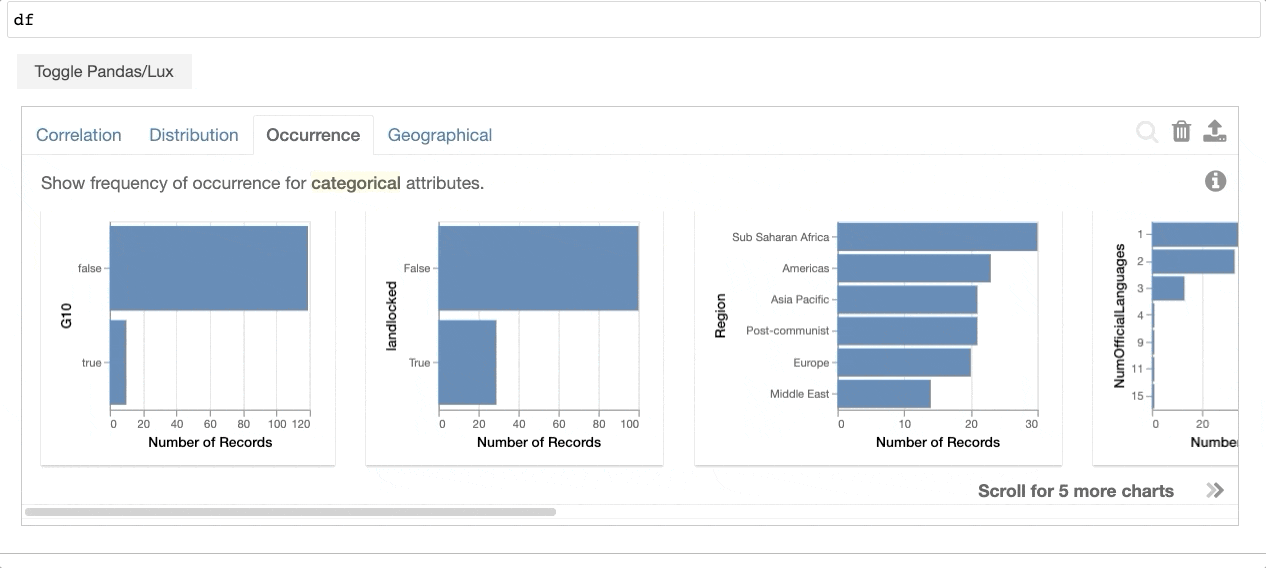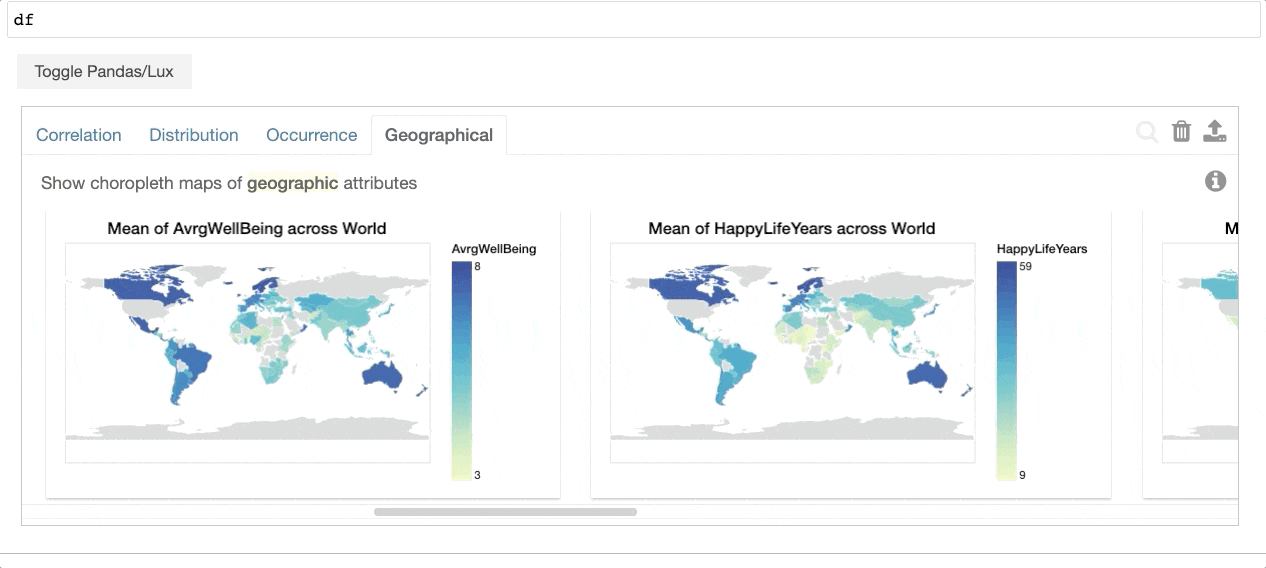{kind=link}
D-Tale
D-Tale 是用於視覺化 pandas 資料結構的輕量級網路用戶端。它提供了一個豐富的試算表風格網格,作為許多 pandas 功能(查詢、排序、描述、相關性...)的包裝器,因此使用者可以快速操作他們的資料。還有一個使用 Plotly Dash 的互動式圖表建構器,讓使用者可以建立漂亮的可攜式視覺化。D-Tale 可以使用下列指令呼叫
import dtale
dtale.show(df)
D-Tale 可以與 Jupyter 筆記本、Python 終端機、Kaggle 和 Google Colab 無縫整合。以下是 網格 的一些示範。
hvplot
hvPlot 是一個建立在 HoloViews 上,供 PyData 生態系統使用的進階繪圖 API。它可以透過以下方式載入為 Pandas 原生繪圖後端
pd.set_option("plotting.backend", "hvplot")
IDE
IPython
IPython 是一個互動式命令殼和分散式運算環境。IPython 標籤完成功能適用於 Pandas 方法,以及 DataFrame 欄位等屬性。
Jupyter Notebook / Jupyter Lab
Jupyter Notebook 是一個用於建立 Jupyter 筆記本的網路應用程式。Jupyter 筆記本是一個 JSON 文件,其中包含一個輸入/輸出儲存格的有序清單,這些儲存格可以包含程式碼、文字、數學、繪圖和豐富媒體。Jupyter 筆記本可以透過網路介面的「另存為」和殼層中的「jupyter convert」轉換為多種開放標準輸出格式(HTML、HTML 簡報投影片、LaTeX、PDF、ReStructuredText、Markdown、Python)。
Pandas DataFrames 實作了 Jupyter Notebook 用於顯示(簡略)HTML 或 LaTeX 表格的 _repr_html_ 和 _repr_latex 方法。LaTeX 輸出經過適當跳脫。(注意:HTML 表格可能與非 HTML Jupyter 輸出格式相容,也可能不相容。)
請參閱 選項和設定 以取得 Pandas 的 display. 設定。
Spyder
Spyder 是一個跨平台的基於 PyQt 的 IDE,它結合了軟體開發工具的編輯、分析、偵錯和分析功能,以及 MATLAB 或 Rstudio 等科學環境的資料探勘、互動執行、深入檢查和豐富視覺化功能。
它的 變數瀏覽器 允許使用者檢視、操作和編輯 Pandas 的 Index、Series 和 DataFrame 物件,就像「試算表」一樣,包括複製和修改值、排序、顯示「熱力圖」、轉換資料類型等等。Pandas 物件也可以重新命名、複製、新增新欄位、從/貼到剪貼簿(為 TSV 格式),以及儲存/載入到/從檔案。Spyder 也可以透過一個進階的匯入精靈,從各種純文字和二進位檔案或剪貼簿匯入資料到新的 Pandas DataFrame。
Spyder 的 編輯器 和 IPython 主控台 中,大部分的 pandas 類別、方法和資料屬性都可以自動完成,而 Spyder 的 說明窗格 可以自動或依需求擷取並呈現 pandas 物件的 Numpydoc 文件,並以 Sphinx 顯示為豐富文字。
API
pandas-datareader
pandas-datareader 是 pandas 的遠端資料存取函式庫 (PyPI:pandas-datareader)。它基於 pandas.io.data 和 pandas.io.wb 中的功能,但在 v0.19 中已分開。在 pandas-datareader 文件 中查看更多資訊。
有下列資料饋送可用
- Google Finance
- Tiingo
- Morningstar
- IEX
- Robinhood
- Enigma
- Quandl
- FRED
- Fama/French
- World Bank
- OECD
- Eurostat
- TSP Fund Data
- Nasdaq Trader Symbol Definitions
- Stooq Index Data
- MOEX Data
pandaSDMX
pandaSDMX 是用來擷取和取得統計資料和元資料的函式庫,這些資料和元資料散布在 SDMX 2.1 中,SDMX 2.1 是統計局、中央銀行和國際組織等機構廣泛使用的 ISO 標準。pandaSDMX 可以將資料集和相關結構化元資料(包括資料流程、代碼清單和資料結構定義)顯示為 pandas Series 或 MultiIndexed DataFrames。
fredapi
fredapi 是 Python 介面,用於存取聖路易聯邦準備銀行提供的 聯邦準備經濟資料 (FRED)。它適用於 FRED 資料庫和 ALFRED 資料庫,其中包含特定時間點的資料(即歷史資料修訂)。fredapi 在 Python 中提供 FRED HTTP API 的包裝器,並提供多種便利的方法,用於分析和分析 ALFRED 中特定時間點的資料。fredapi 使用 pandas,並以 Series 或 DataFrame 的形式傳回資料。此模組需要 FRED API 金鑰,您可以在 FRED 網站上免費取得。
特定領域
Geopandas
Geopandas 擴充 pandas 資料物件,以納入支援幾何運算的地理資訊。如果您工作的內容涉及地圖和地理座標,而且您喜歡 pandas,您應該仔細看看 Geopandas。
gurobipy-pandas
gurobipy-pandas 提供便利的存取器 API,以將 pandas 與 gurobipy 連接起來。它讓使用者能夠更輕鬆、更有效率地從儲存在資料框和序列中的資料建立數學最佳化模型,並將解讀回 pandas 物件。
staircase
staircase 是建立在 pandas 和 numpy 上的資料分析套件,用於數學階梯函數的建模和操作。它提供豐富的算術運算、關係運算、邏輯運算、統計運算和聚合,用於定義在實數、日期時間和時間差域上的階梯函數。
xarray
xarray 將 pandas 的標籤資料功能帶入物理科學,提供 N 維的 pandas 核心資料結構變體。它的目標是提供一個類似 pandas 且與 pandas 相容的工具包,用於分析多維陣列,而不是 pandas 擅長的表格資料。
IO
NTV-pandas
NTV-pandas 提供 JSON 轉換器,其資料類型比 pandas 直接支援的資料類型更多。
它支援下列資料類型
介面始終是可逆的(轉換往返)且有兩種格式(JSON-NTV 和 JSON-TableSchema)。
範例
import ntv_pandas as npd
jsn = df.npd.to_json(table=False) # save df as a JSON-value (format Table Schema if table is True else format NTV )
df = npd.read_json(jsn) # load a JSON-value as a `DataFrame`
df.equals(npd.read_json(df.npd.to_json(df))) # `True` in any case, whether `table=True` or not
BCPandas
BCPandas 提供從 pandas 寫入 Microsoft SQL Server 的高性能,遠遠超過原生 df.to_sql 方法的性能。在內部,它使用 Microsoft 的 BCP 工具程式,但複雜性完全對最終使用者隱藏。經過嚴格測試,它是 df.to_sql 的完整替代品。
Deltalake
Deltalake python 套件讓您可以原生於 Python 中存取儲存在 Delta Lake 中的表格,無需使用 Spark 或 JVM。它提供 delta_table.to_pyarrow_table().to_pandas() 方法,將任何 Delta 表格轉換成 Pandas 資料框。
核心外
Cylon
Cylon 是一個快速、可擴充、分散式記憶體平行執行時間,具有類似 pandas 的 Python DataFrame API。「核心 Cylon」使用 C++ 實作,使用 Apache Arrow 格式來表示記憶體中的資料。Cylon DataFrame API 實作了大多數 pandas 的核心運算子,例如合併、篩選、聯結、串接、群組、刪除重複值等。這些運算子設計為可在數千個核心上執行,以擴充應用程式。它可以透過從 pandas 讀取資料或將資料轉換成 pandas,與 pandas DataFrame 互通,因此使用者可以選擇性地擴充其 pandas DataFrame 應用程式的部分。
from pycylon import read_csv, DataFrame, CylonEnv
from pycylon.net import MPIConfig
# Initialize Cylon distributed environment
config: MPIConfig = MPIConfig()
env: CylonEnv = CylonEnv(config=config, distributed=True)
df1: DataFrame = read_csv('/tmp/csv1.csv')
df2: DataFrame = read_csv('/tmp/csv2.csv')
# Using 1000s of cores across the cluster to compute the join
df3: Table = df1.join(other=df2, on=[0], algorithm="hash", env=env)
print(df3)
Dask
Dask 是用於分析的彈性平行運算函式庫。Dask 提供一個熟悉的 DataFrame 介面,用於核心外、平行和分散式運算。
Dask-ML
Dask-ML 使用 Dask 與現有的機器學習函式庫(例如 Scikit-Learn、XGBoost 和 TensorFlow)一起啟用平行和分散式機器學習。
Ibis
Ibis 提供一種撰寫分析程式碼的標準方式,可以在多個引擎中執行。它有助於縮小本地 Python 環境(例如 pandas)與遠端儲存和執行系統(例如 Hadoop 元件(例如 HDFS、Impala、Hive、Spark)和 SQL 資料庫(Postgres 等))之間的差距。
Koalas
Koalas 在 Apache Spark 上方提供一個熟悉的 pandas DataFrame 介面。它使用戶能夠利用單一機器或多台機器叢集上的多核心,來加速或擴充其 DataFrame 程式碼。
Modin
modin.pandas DataFrame 是 pandas 的平行和分散式替代品。這表示您可以將 Modin 與現有的 pandas 程式碼一起使用,或使用現有的 pandas API 編寫新程式碼。Modin 可以利用您的整台機器或叢集來加速和擴充您的 pandas 工作負載,包括傳統上耗時的任務,例如資料擷取 (read_csv、read_excel、read_parquet 等)。
# import pandas as pd
import modin.pandas as pd
df = pd.read_csv("big.csv") # use all your cores!
Pandarallel
Pandarallel 提供一種簡單的方法,只需變更一行程式碼,即可在所有 CPU 上平行化您的 pandas 作業。它也會顯示進度條。
from pandarallel import pandarallel
pandarallel.initialize(progress_bar=True)
# df.apply(func)
df.parallel_apply(func)
Vaex
越來越多的套件建構在 pandas 之上,以滿足資料準備、分析和視覺化的特定需求。Vaex 是 Python 函式庫,用於 Out-of-Core DataFrames (類似於 Pandas),以視覺化和探索大型表格化資料集。它可以計算統計資料,例如平均值、總和、計數、標準差等,在 N 維網格上,每秒最多可達十億 (10^9) 個物件/列。視覺化使用直方圖、密度圖和 3D 體積渲染完成,允許互動式探索大資料。Vaex 使用記憶體對應、零記憶體複製政策和延遲運算來獲得最佳效能 (不浪費記憶體)。
vaex.from_pandasvaex.to_pandas_df
Hail Query
一個 Out-of-core、可搶先式安全、分散式資料框函式庫,服務於遺傳學社群。Hail Query 隨附磁碟資料格式、記憶體中資料格式、表達式編譯器、查詢規劃器和分散式排序演算法,所有這些都旨在加速對大型基因組定序資料矩陣的查詢。
通常最簡單的方法是使用 pandas 來處理 Hail 產生的摘要統計資料或其他小型彙總。因此,Hail 提供原生匯入和匯出 pandas DataFrames
資料清理和驗證
pyjanitor
Pyjanitor 提供一個乾淨的 API 來清理資料,使用方法鏈結。
Pandera
Pandera 提供一個彈性且具表現力的 API,用於對資料框執行資料驗證,以使資料處理管線更具可讀性和穩健性。資料框包含 Pandera 在執行階段明確驗證的資訊。這在生產關鍵資料管線或可重製的研究設定中很有用。
延伸資料類型
Pandas 提供一個介面,用於定義 延伸類型 以延伸 NumPy 的類型系統。下列函式庫實作該介面,以提供 NumPy 或 Pandas 中找不到的類型,這些類型與 Pandas 的資料容器搭配使用效果良好。
awkward-pandas
Awkward-pandas 提供一個延伸類型,用於將 Awkward Arrays 儲存在 Pandas 的 Series 和 DataFrame 中。它還提供一個存取器,用於對 awkward 類型的 Series 使用 awkward 函數。
Pandas-Genomics
Pandas-Genomics 提供一個延伸類型和延伸陣列,用於處理基因體資料。它還包含 `genomics` 存取器,用於許多與基因體資料的 QC 和分析相關的有用屬性和方法。
Physipandas
Physipandas 提供一個延伸,用於處理物理量(例如純量和 numpy.ndarray),並與物理單位(例如公尺或焦耳)關聯,以及其他功能,用於將 `physipy` 存取器與 Pandas Series 和 Dataframe 整合。
Pint-Pandas
Pint-Pandas 提供一個延伸類型,用於儲存帶有單位的數值陣列。這些陣列可以儲存在 Pandas 的 Series 和 DataFrame 中。然後,使用 Pint 延伸陣列的 Series 和 DataFrame 欄位之間的運算會感知單位。
文字延伸
Pandas 的文字擴充套件提供擴充套件類型,涵蓋用於表示自然語言資料的常見資料結構,以及將熱門自然語言處理函式庫的輸出轉換成 Pandas 資料框的函式庫整合。
存取器
提供 擴充套件存取器 的專案目錄。這是讓使用者發現新存取器,以及讓函式庫作者在命名空間上進行協調。
| 函式庫 | 存取器 | 類別 |
|---|---|---|
| awkward-pandas | ak |
Series |
| pdvega | vgplot |
Series、DataFrame |
| pandas-genomics | genomics |
Series、DataFrame |
| pint-pandas | pint |
Series、DataFrame |
| physipandas | physipy |
Series、DataFrame |
| composeml | slice |
DataFrame |
| gurobipy-pandas | gppd |
Series、DataFrame |
| staircase | sc |
Series、DataFrame |
| woodwork | slice |
Series、DataFrame |
開發工具
pandas-stubs
雖然 pandas 儲存庫已部分類型化,但套件本身並未公開此資訊供外部使用。安裝 pandas-stubs 以啟用 pandas API 的基本類型涵蓋範圍。
透過閱讀下列議題了解更多資訊:14468、26766、28142。
請參閱 GitHub 頁面 上的安裝和使用說明。
Hamilton
Hamilton 是 Stitch Fix 推出的宣告式資料流程架構。它旨在協助管理 Pandas 程式碼庫,特別是在機器學習模型的特徵工程方面。
它規定了一個有見解的範例,確保所有程式碼
- 單元可測試
- 整合測試友善
- 文件友善
- 轉換邏輯可重複使用,因為它與使用它的環境脫鉤。
- 可與執行階段資料品質檢查整合。
這有助於擴充 Pandas 程式碼庫,同時降低維護成本。
如需更多資訊,請參閱 文件。