In [1]: import pandas as pd
In [2]: import matplotlib.pyplot as plt
-
空氣品質資料
In [3]: air_quality = pd.read_csv("data/air_quality_no2_long.csv") In [4]: air_quality = air_quality.rename(columns={"date.utc": "datetime"}) In [5]: air_quality.head() Out[5]: city country datetime location parameter value unit 0 Paris FR 2019-06-21 00:00:00+00:00 FR04014 no2 20.0 µg/m³ 1 Paris FR 2019-06-20 23:00:00+00:00 FR04014 no2 21.8 µg/m³ 2 Paris FR 2019-06-20 22:00:00+00:00 FR04014 no2 26.5 µg/m³ 3 Paris FR 2019-06-20 21:00:00+00:00 FR04014 no2 24.9 µg/m³ 4 Paris FR 2019-06-20 20:00:00+00:00 FR04014 no2 21.4 µg/m³
In [6]: air_quality.city.unique() Out[6]: array(['Paris', 'Antwerpen', 'London'], dtype=object)
如何輕鬆處理時間序列資料#
使用 pandas datetime 屬性#
我想將
datetime欄中的日期當成 datetime 物件,而不是純文字In [7]: air_quality["datetime"] = pd.to_datetime(air_quality["datetime"]) In [8]: air_quality["datetime"] Out[8]: 0 2019-06-21 00:00:00+00:00 1 2019-06-20 23:00:00+00:00 2 2019-06-20 22:00:00+00:00 3 2019-06-20 21:00:00+00:00 4 2019-06-20 20:00:00+00:00 ... 2063 2019-05-07 06:00:00+00:00 2064 2019-05-07 04:00:00+00:00 2065 2019-05-07 03:00:00+00:00 2066 2019-05-07 02:00:00+00:00 2067 2019-05-07 01:00:00+00:00 Name: datetime, Length: 2068, dtype: datetime64[ns, UTC]
最初,
datetime中的值為字串,且不提供任何 datetime 操作(例如:擷取年份、星期幾等)。透過套用to_datetime函式,pandas 會詮釋字串,並將其轉換成 datetime(亦即datetime64[ns, UTC])物件。在 pandas 中,我們將這些 datetime 物件稱為pandas.Timestamp,類似於標準函式庫中的datetime.datetime。
注意
由於許多資料集都包含其中一欄的日期時間資訊,因此 pandas 的輸入函式,例如 pandas.read_csv() 和 pandas.read_json() 可在使用 parse_dates 參數讀取資料時,將其轉換為日期,其中包含要作為時間戳記讀取的欄位清單
pd.read_csv("../data/air_quality_no2_long.csv", parse_dates=["datetime"])
為何這些 pandas.Timestamp 物件很有用?讓我們透過一些範例案例來說明其附加價值。
我們正在處理的時間序列資料集的開始和結束日期為何?
In [9]: air_quality["datetime"].min(), air_quality["datetime"].max()
Out[9]:
(Timestamp('2019-05-07 01:00:00+0000', tz='UTC'),
Timestamp('2019-06-21 00:00:00+0000', tz='UTC'))
使用 pandas.Timestamp 來處理日期時間,讓我們能夠計算日期資訊,並使其可比較。因此,我們可以使用它來取得時間序列的長度
In [10]: air_quality["datetime"].max() - air_quality["datetime"].min()
Out[10]: Timedelta('44 days 23:00:00')
結果是一個 pandas.Timedelta 物件,類似於標準 Python 函式庫中的 datetime.timedelta,用於定義時間持續時間。
pandas 支援的各種時間概念在使用者指南的 時間相關概念 部分中說明。
我想在
DataFrame中新增一欄,其中只包含測量月份In [11]: air_quality["month"] = air_quality["datetime"].dt.month In [12]: air_quality.head() Out[12]: city country datetime ... value unit month 0 Paris FR 2019-06-21 00:00:00+00:00 ... 20.0 µg/m³ 6 1 Paris FR 2019-06-20 23:00:00+00:00 ... 21.8 µg/m³ 6 2 Paris FR 2019-06-20 22:00:00+00:00 ... 26.5 µg/m³ 6 3 Paris FR 2019-06-20 21:00:00+00:00 ... 24.9 µg/m³ 6 4 Paris FR 2019-06-20 20:00:00+00:00 ... 21.4 µg/m³ 6 [5 rows x 8 columns]
透過使用
Timestamp物件作為日期,pandas 提供了許多與時間相關的屬性。例如month,還有year、quarter,… 所有這些屬性都可以透過dt存取器存取。
現有日期屬性的概觀,請參閱 時間和日期元件概觀表格。有關 dt 存取器用於傳回日期時間類似屬性的更多詳細資料,請參閱 dt 存取器 的專屬區段。
每個測量位置,每週的平均 \(NO_2\) 濃度是多少?
In [13]: air_quality.groupby( ....: [air_quality["datetime"].dt.weekday, "location"])["value"].mean() ....: Out[13]: datetime location 0 BETR801 27.875000 FR04014 24.856250 London Westminster 23.969697 1 BETR801 22.214286 FR04014 30.999359 ... 5 FR04014 25.266154 London Westminster 24.977612 6 BETR801 21.896552 FR04014 23.274306 London Westminster 24.859155 Name: value, Length: 21, dtype: float64
還記得
groupby提供的分割-套用-結合模式嗎?請參閱 統計計算教學?在此,我們想要計算給定的統計資料(例如 \(NO_2\) 的平均值)每個工作日和每個測量位置。若要依工作日進行分組,我們使用 pandasTimestamp的日期時間屬性weekday(星期一=0,星期日=6),也可以透過dt存取器存取。可以在位置和工作日上進行分組,以分割在這些組合中計算平均值。危險
由於我們在這些範例中使用非常短的時間序列,因此分析不會提供長期代表性的結果!
繪製所有測站的時間序列中,一天中典型的 \(NO_2\) 模式。換句話說,一天中每個小時的平均值是多少?
In [14]: fig, axs = plt.subplots(figsize=(12, 4)) In [15]: air_quality.groupby(air_quality["datetime"].dt.hour)["value"].mean().plot( ....: kind='bar', rot=0, ax=axs ....: ) ....: Out[15]: <Axes: xlabel='datetime'> In [16]: plt.xlabel("Hour of the day"); # custom x label using Matplotlib In [17]: plt.ylabel("$NO_2 (µg/m^3)$");
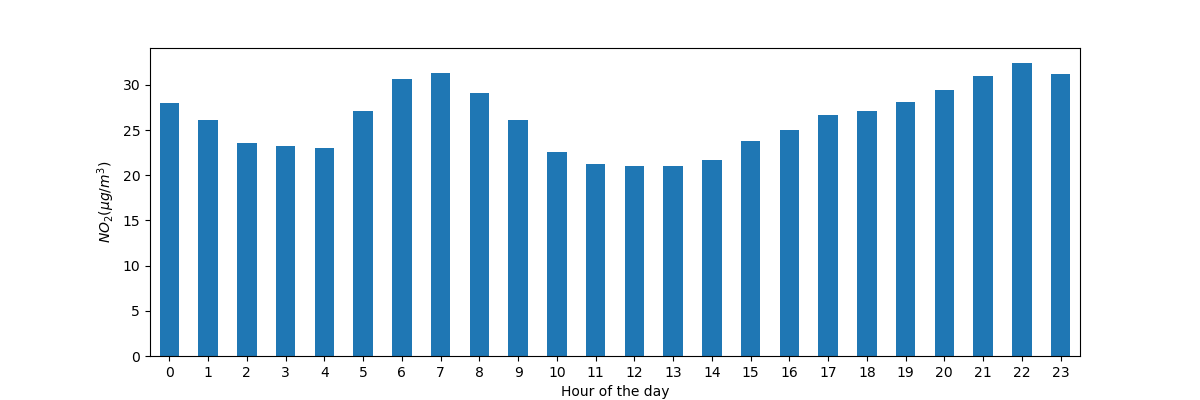
與前一個案例類似,我們想要計算給定的統計量(例如 \(NO_2\) 的平均值),針對一天中的每個小時,我們可以再次使用分割-套用-組合的方法。對於這個案例,我們使用 pandas
Timestamp的 datetime 屬性hour,也可以透過dt存取器存取。
Datetime 作為索引#
在 重塑教學 中,pivot() 被介紹來重塑資料表,讓每個測量位置成為一個獨立的欄位
In [18]: no_2 = air_quality.pivot(index="datetime", columns="location", values="value")
In [19]: no_2.head()
Out[19]:
location BETR801 FR04014 London Westminster
datetime
2019-05-07 01:00:00+00:00 50.5 25.0 23.0
2019-05-07 02:00:00+00:00 45.0 27.7 19.0
2019-05-07 03:00:00+00:00 NaN 50.4 19.0
2019-05-07 04:00:00+00:00 NaN 61.9 16.0
2019-05-07 05:00:00+00:00 NaN 72.4 NaN
注意
透過樞紐化資料,datetime 資訊就變成資料表的索引。一般來說,將欄位設定為索引可以使用 set_index 函數。
使用 datetime 索引(例如 DatetimeIndex)提供了強大的功能。例如,我們不需要 dt 存取器來取得時間序列屬性,而是直接在索引上取得這些屬性
In [20]: no_2.index.year, no_2.index.weekday
Out[20]:
(Index([2019, 2019, 2019, 2019, 2019, 2019, 2019, 2019, 2019, 2019,
...
2019, 2019, 2019, 2019, 2019, 2019, 2019, 2019, 2019, 2019],
dtype='int32', name='datetime', length=1033),
Index([1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
...
3, 3, 3, 3, 3, 3, 3, 3, 3, 4],
dtype='int32', name='datetime', length=1033))
其他一些優點是時間區間的方便子集或圖形上的適應時間比例。讓我們將其應用於我們的資料。
建立從 5 月 20 日到 5 月 21 日結束的不同站點中 \(NO_2\) 值的圖形
In [21]: no_2["2019-05-20":"2019-05-21"].plot();
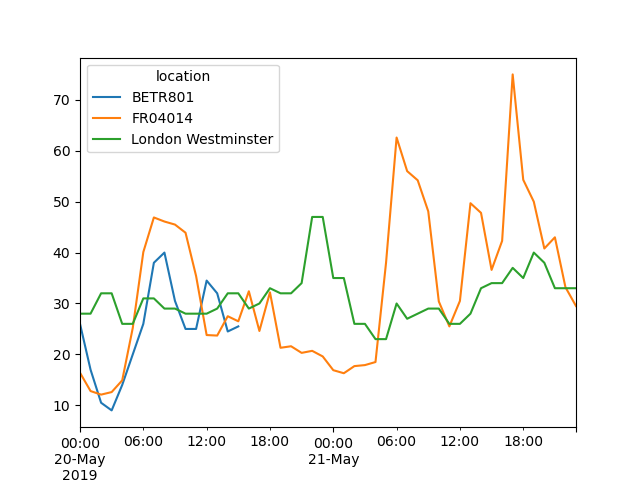
透過提供解析為日期時間的字串,可以在
DatetimeIndex上選取資料的特定子集。
有關 DatetimeIndex 和使用字串切片的更多資訊,請參閱 時間序列索引 部分。
將時間序列重新取樣為另一個頻率#
將目前每小時的時間序列值彙總為每個站點的每月最大值。
In [22]: monthly_max = no_2.resample("ME").max() In [23]: monthly_max Out[23]: location BETR801 FR04014 London Westminster datetime 2019-05-31 00:00:00+00:00 74.5 97.0 97.0 2019-06-30 00:00:00+00:00 52.5 84.7 52.0
具有日期時間索引的時間序列資料中非常強大的方法,是可以
resample()時間序列為另一個頻率(例如,將每秒資料轉換為每 5 分鐘資料)。
resample() 方法類似於 groupby 運算
它提供基於時間的分組,透過使用定義目標頻率的字串(例如
M、5H,…)它需要一個聚合函數,例如
mean、max等。
在 偏移別名總覽表 中提供了用於定義時間序列頻率的別名的概觀。
定義時,時間序列的頻率由 freq 屬性提供
In [24]: monthly_max.index.freq
Out[24]: <MonthEnd>
繪製每個站點中每日平均 \(NO_2\) 值的圖形。
In [25]: no_2.resample("D").mean().plot(style="-o", figsize=(10, 5));
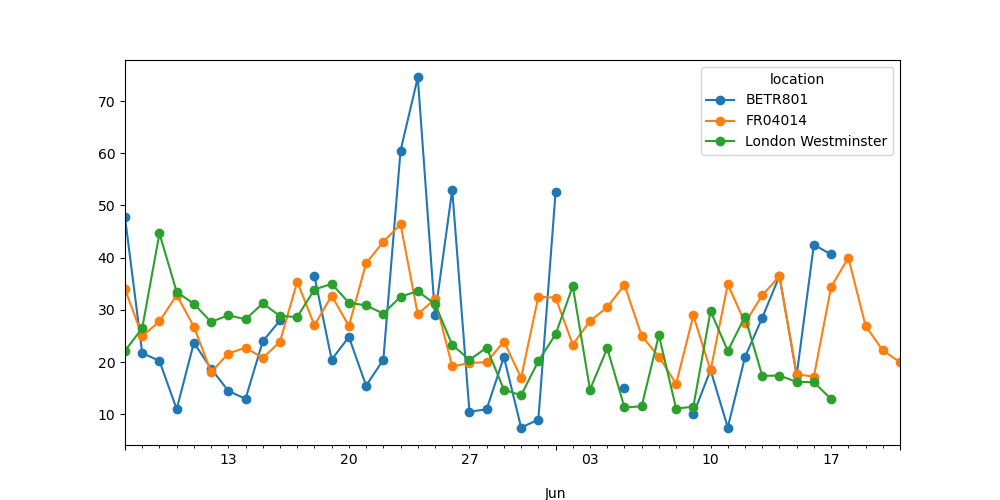
在 重新採樣 的使用者指南部分中提供了有關時間序列 resampling 功能的更多詳細資訊。
請記住
可以使用
to_datetime函數或作為讀取函數的一部分,將有效的日期字串轉換為日期時間物件。使用
dt存取器,pandas 中的日期時間物件支援計算、邏輯運算和便利的日期相關屬性。一個
DatetimeIndex包含這些日期相關屬性,並支援便利的切片。Resample是一個強大的方法,用於變更時間序列的頻率。
在 時間序列和日期功能 的頁面上提供了時間序列的完整概觀。