In [1]: import pandas as pd
- 鐵達尼號資料
本教學課程使用以 CSV 儲存的鐵達尼號資料集。資料包含下列資料欄位
PassengerId:每位乘客的 ID。
Survived:表示乘客是否存活。
0表示是,1表示否。Pclass:三個票價等級之一:頭等艙
1、二等艙2和三等艙3。Name:乘客姓名。
Sex:乘客性別。
Age:乘客年齡(歲)。
SibSp:船上兄弟姊妹或配偶人數。
Parch:船上父母或子女人數。
Ticket:乘客的船票號碼。
Fare:表示票價。
Cabin:乘客的船艙號碼。
Embarked:登船港口。
In [2]: titanic = pd.read_csv("data/titanic.csv") In [3]: titanic.head() Out[3]: PassengerId Survived Pclass ... Fare Cabin Embarked 0 1 0 3 ... 7.2500 NaN S 1 2 1 1 ... 71.2833 C85 C 2 3 1 3 ... 7.9250 NaN S 3 4 1 1 ... 53.1000 C123 S 4 5 0 3 ... 8.0500 NaN S [5 rows x 12 columns]
-
空氣品質資料
本教學使用 OpenAQ 提供的空氣品質資料,資料內容包含 \(NO_2\) 和小於 2.5 微米的懸浮微粒,並使用 py-openaq 套件。
air_quality_long.csv資料集提供巴黎、安特衛普和倫敦的測量站 FR04014、BETR801 和 London Westminster 的 \(NO_2\) 和 \(PM_{25}\) 值。空氣品質資料集包含下列欄位
city:感測器使用地點的城市,可能是巴黎、安特衛普或倫敦
country:感測器使用地點的國家,可能是法國、比利時或英國
location:感測器的 ID,可能是 FR04014、BETR801 或 London Westminster
parameter:感測器測量的參數,可能是 \(NO_2\) 或懸浮微粒
value:測量值
unit:測量參數的單位,在本例中為「µg/m³」
而
DataFrame的索引為datetime,也就是測量的日期時間。至原始資料注意
空氣品質資料以所謂的長格式資料表示,每一筆觀測資料都在個別列中,而每個變數都是資料表的個別欄位。長/窄格式也稱為 整齊資料格式。
In [4]: air_quality = pd.read_csv( ...: "data/air_quality_long.csv", index_col="date.utc", parse_dates=True ...: ) ...: In [5]: air_quality.head() Out[5]: city country location parameter value unit date.utc 2019-06-18 06:00:00+00:00 Antwerpen BE BETR801 pm25 18.0 µg/m³ 2019-06-17 08:00:00+00:00 Antwerpen BE BETR801 pm25 6.5 µg/m³ 2019-06-17 07:00:00+00:00 Antwerpen BE BETR801 pm25 18.5 µg/m³ 2019-06-17 06:00:00+00:00 Antwerpen BE BETR801 pm25 16.0 µg/m³ 2019-06-17 05:00:00+00:00 Antwerpen BE BETR801 pm25 7.5 µg/m³
如何變更表格的配置#
排序表格列#
我想依乘客年齡排序鐵達尼號資料。
In [6]: titanic.sort_values(by="Age").head() Out[6]: PassengerId Survived Pclass ... Fare Cabin Embarked 803 804 1 3 ... 8.5167 NaN C 755 756 1 2 ... 14.5000 NaN S 644 645 1 3 ... 19.2583 NaN C 469 470 1 3 ... 19.2583 NaN C 78 79 1 2 ... 29.0000 NaN S [5 rows x 12 columns]
我想依艙等和年齡降冪排序鐵達尼號資料。
In [7]: titanic.sort_values(by=['Pclass', 'Age'], ascending=False).head() Out[7]: PassengerId Survived Pclass ... Fare Cabin Embarked 851 852 0 3 ... 7.7750 NaN S 116 117 0 3 ... 7.7500 NaN Q 280 281 0 3 ... 7.7500 NaN Q 483 484 1 3 ... 9.5875 NaN S 326 327 0 3 ... 6.2375 NaN S [5 rows x 12 columns]
使用
DataFrame.sort_values(),表格中的列會根據定義的欄位進行排序。索引將遵循列順序。
有關表格排序的更多詳細資訊,請參閱使用者指南中關於 資料排序 的部分。
長表格轉換為寬表格格式#
我們使用空氣品質資料集的一個小部分。我們專注於 \(NO_2\) 資料,並且僅使用每個位置的前兩次測量(即每個群組的開頭)。資料的子集將稱為 no2_subset。
# filter for no2 data only
In [8]: no2 = air_quality[air_quality["parameter"] == "no2"]
# use 2 measurements (head) for each location (groupby)
In [9]: no2_subset = no2.sort_index().groupby(["location"]).head(2)
In [10]: no2_subset
Out[10]:
city country ... value unit
date.utc ...
2019-04-09 01:00:00+00:00 Antwerpen BE ... 22.5 µg/m³
2019-04-09 01:00:00+00:00 Paris FR ... 24.4 µg/m³
2019-04-09 02:00:00+00:00 London GB ... 67.0 µg/m³
2019-04-09 02:00:00+00:00 Antwerpen BE ... 53.5 µg/m³
2019-04-09 02:00:00+00:00 Paris FR ... 27.4 µg/m³
2019-04-09 03:00:00+00:00 London GB ... 67.0 µg/m³
[6 rows x 6 columns]

我希望將三個測站的值作為彼此相鄰的獨立欄位。
In [11]: no2_subset.pivot(columns="location", values="value") Out[11]: location BETR801 FR04014 London Westminster date.utc 2019-04-09 01:00:00+00:00 22.5 24.4 NaN 2019-04-09 02:00:00+00:00 53.5 27.4 67.0 2019-04-09 03:00:00+00:00 NaN NaN 67.0
pivot()函數純粹是重新調整資料形狀:需要每個索引/欄位組合的單一值。
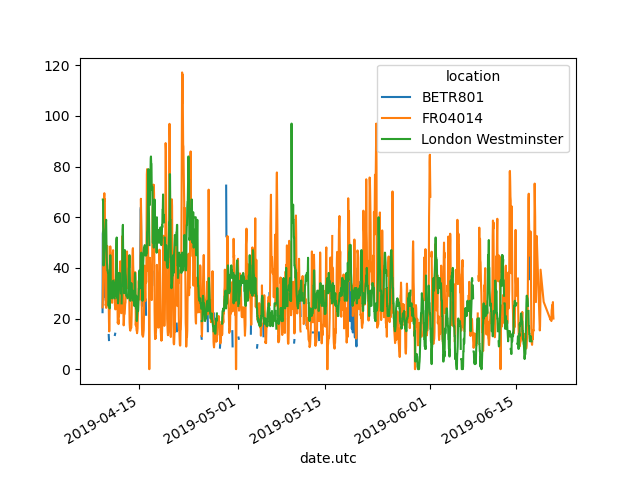
由於 pandas 支援多個欄位的繪製(請參閱 繪製教學),因此從長表格轉換為寬表格格式可以同時繪製不同的時間序列
In [12]: no2.head()
Out[12]:
city country location parameter value unit
date.utc
2019-06-21 00:00:00+00:00 Paris FR FR04014 no2 20.0 µg/m³
2019-06-20 23:00:00+00:00 Paris FR FR04014 no2 21.8 µg/m³
2019-06-20 22:00:00+00:00 Paris FR FR04014 no2 26.5 µg/m³
2019-06-20 21:00:00+00:00 Paris FR FR04014 no2 24.9 µg/m³
2019-06-20 20:00:00+00:00 Paris FR FR04014 no2 21.4 µg/m³
In [13]: no2.pivot(columns="location", values="value").plot()
Out[13]: <Axes: xlabel='date.utc'>
注意
當未定義 index 參數時,將使用現有的索引(列標籤)。
有關 pivot() 的更多資訊,請參閱使用者指南中關於 樞紐 DataFrame 物件 的部分。
樞紐表格#

我希望以表格形式顯示每個測站中 \(NO_2\) 和 \(PM_{2.5}\) 的平均濃度。
In [14]: air_quality.pivot_table( ....: values="value", index="location", columns="parameter", aggfunc="mean" ....: ) ....: Out[14]: parameter no2 pm25 location BETR801 26.950920 23.169492 FR04014 29.374284 NaN London Westminster 29.740050 13.443568
在
pivot()的情況下,資料僅重新排列。當需要彙總多個值(在此特定情況下,不同時間步驟上的值)時,可以使用pivot_table(),提供彙總函數(例如平均值)來組合這些值。
樞紐分析表是試算表軟體中一個眾所周知的概念。當對每個變數的列/欄邊界(小計)有興趣時,將 margins 參數設定為 True
In [15]: air_quality.pivot_table(
....: values="value",
....: index="location",
....: columns="parameter",
....: aggfunc="mean",
....: margins=True,
....: )
....:
Out[15]:
parameter no2 pm25 All
location
BETR801 26.950920 23.169492 24.982353
FR04014 29.374284 NaN 29.374284
London Westminster 29.740050 13.443568 21.491708
All 29.430316 14.386849 24.222743
有關 pivot_table() 的詳細資訊,請參閱使用者指南中關於 樞紐分析表 的區段。
注意
如果您想知道,pivot_table() 確實與 groupby() 直接連結。可以在 parameter 和 location 上進行分組,以得出相同的結果
air_quality.groupby(["parameter", "location"])[["value"]].mean()
寬廣至長條格式#
從前一節建立的寬格式表格重新開始,我們使用 reset_index(),將新的索引加入 DataFrame。
In [16]: no2_pivoted = no2.pivot(columns="location", values="value").reset_index()
In [17]: no2_pivoted.head()
Out[17]:
location date.utc BETR801 FR04014 London Westminster
0 2019-04-09 01:00:00+00:00 22.5 24.4 NaN
1 2019-04-09 02:00:00+00:00 53.5 27.4 67.0
2 2019-04-09 03:00:00+00:00 54.5 34.2 67.0
3 2019-04-09 04:00:00+00:00 34.5 48.5 41.0
4 2019-04-09 05:00:00+00:00 46.5 59.5 41.0

我想在單一欄位(長格式)中收集所有空氣品質 \(NO_2\) 測量值。
In [18]: no_2 = no2_pivoted.melt(id_vars="date.utc") In [19]: no_2.head() Out[19]: date.utc location value 0 2019-04-09 01:00:00+00:00 BETR801 22.5 1 2019-04-09 02:00:00+00:00 BETR801 53.5 2 2019-04-09 03:00:00+00:00 BETR801 54.5 3 2019-04-09 04:00:00+00:00 BETR801 34.5 4 2019-04-09 05:00:00+00:00 BETR801 46.5
DataFrame上的pandas.melt()方法會將資料表格從寬格式轉換成長格式。欄位標題會變成新建立欄位中的變數名稱。
解決方案是應用 pandas.melt() 的簡短版本。此方法會將未在 id_vars 中提到的所有欄位熔解成兩個欄位:一個欄位包含欄位標題名稱,另一個欄位包含值本身。後者的欄位名稱預設為 value。
傳遞給 pandas.melt() 的參數可以更詳細地定義
In [20]: no_2 = no2_pivoted.melt(
....: id_vars="date.utc",
....: value_vars=["BETR801", "FR04014", "London Westminster"],
....: value_name="NO_2",
....: var_name="id_location",
....: )
....:
In [21]: no_2.head()
Out[21]:
date.utc id_location NO_2
0 2019-04-09 01:00:00+00:00 BETR801 22.5
1 2019-04-09 02:00:00+00:00 BETR801 53.5
2 2019-04-09 03:00:00+00:00 BETR801 54.5
3 2019-04-09 04:00:00+00:00 BETR801 34.5
4 2019-04-09 05:00:00+00:00 BETR801 46.5
其他參數具有以下效果
value_vars定義要熔解在一起的欄位value_name提供自訂欄位名稱給值欄位,而非預設欄位名稱valuevar_name提供自訂欄位名稱給收集欄位標題名稱的欄位。否則,它會採用索引名稱或預設variable
因此,引數 value_name 和 var_name 只是使用者定義的名稱,用於兩個產生的欄位。要融化的欄位由 id_vars 和 value_vars 定義。
使用 pandas.melt() 從寬式轉換成長式格式,說明在使用者指南的 透過融化變形 區段。
請記住
使用
sort_values支援依一個或多個欄位排序。pivot函數純粹是重新調整資料結構,pivot_table支援聚合。pivot的反向(長式轉換為寬式格式)是melt(寬式轉換為長式格式)。
完整概觀可在使用者指南的 變形和樞紐 頁面中取得。