貢獻程式碼庫#
程式碼標準#
撰寫良好的程式碼不僅與您撰寫的內容有關。它也與您如何撰寫有關。在 持續整合 測試期間,將執行多個工具來檢查您的程式碼是否有樣式錯誤。產生任何警告將導致測試失敗。因此,良好的樣式是提交程式碼至 pandas 的必要條件。
pandas 中有幾個工具可協助貢獻者在貢獻專案前驗證他們的變更
./ci/code_checks.sh:一個腳本驗證文件範例、文件字串中的格式化以及匯入的模組。可以使用參數docstrings、code和doctests獨立執行檢查(例如./ci/code_checks.sh doctests);pre-commit,我們將在下一節中詳細說明。
此外,由於許多人使用我們的程式庫,因此我們不要對程式碼進行突然的變更,這可能會導致許多使用者程式碼中斷,也就是說,我們需要讓它盡可能地向後相容,以避免大規模中斷。
Pre-commit#
此外,持續整合將執行程式碼格式檢查,例如 black、ruff、isort 和 clang-format,以及使用 pre-commit hooks 的更多檢查。這些檢查的任何警告都將導致 持續整合 失敗;因此,在提交程式碼之前自行執行檢查會很有幫助。這可以透過安裝 pre-commit 來完成(如果您按照 設定您的開發環境 中的說明進行操作,應該已經完成),然後執行
pre-commit install
從 pandas 儲存庫的根目錄。現在,每次提交變更時,都會執行所有樣式檢查,而無需手動執行每個檢查。此外,使用 pre-commit 還可以讓您更輕鬆地隨時了解我們的程式碼檢查,因為它們會隨著時間而改變。
請注意,如果需要,你可以使用 git commit --no-verify 來跳過這些檢查。
如果你不想在工作流程中使用 pre-commit,你仍然可以使用它來執行其檢查,方法如下
pre-commit run --files <files you have modified>
pre-commit run --from-ref=upstream/main --to-ref=HEAD --all-files
無需事先執行 pre-commit install。
最後,我們還有一些緩慢的提交前檢查,它們不會在每次提交時執行,但會在持續整合期間執行。你可以使用以下命令手動觸發它們
pre-commit run --hook-stage manual --all-files
注意
你可能希望定期執行 pre-commit gc,以清理不再使用的儲存庫。
注意
如果你有衝突的 virtualenv 安裝,則可能會收到錯誤 - 請參閱 這裡。
此外,由於 virtualenv 中的錯誤,如果你使用 conda,可能會遇到問題。為了解決此問題,你可以將 virtualenv 降級到 20.0.33 版本。
注意
如果你最近從上游分支合併了 main,pre-commit 使用的一些依賴項可能已更改。請務必 更新你的開發環境。
選用相依性#
選用相依性(例如 matplotlib)應使用私有輔助程式 pandas.compat._optional.import_optional_dependency 匯入。當相依性未滿足時,這可確保一致的錯誤訊息。
所有使用選用相依性的方法都應包含一個測試,斷言當找不到選用相依性時會引發 ImportError。如果程式庫存在,則應略過此測試。
所有選用相依性都應記載於 選用相依性,且應在 pandas.compat._optional.VERSIONS 字典中設定最低所需版本。
向下相容性#
請嘗試維持向下相容性。pandas 有許多使用者,且有許多現有程式碼,因此請盡可能不要中斷它。如果您認為需要中斷,請在提交請求中清楚說明原因。此外,變更方法簽章時請小心,並在需要時加入不建議使用的警告。此外,將不建議使用的 sphinx 指令加入不建議使用的函數或方法。
如果存在與不建議使用的函數具有相同引數的函數,您可以使用 pandas.util._decorators.deprecate
from pandas.util._decorators import deprecate
deprecate('old_func', 'new_func', '1.1.0')
否則,您需要手動執行
import warnings
from pandas.util._exceptions import find_stack_level
def old_func():
"""Summary of the function.
.. deprecated:: 1.1.0
Use new_func instead.
"""
warnings.warn(
'Use new_func instead.',
FutureWarning,
stacklevel=find_stack_level(),
)
new_func()
def new_func():
pass
您還需要
撰寫一個新的測試,斷言使用不建議使用的引數呼叫時會發出警告
更新所有現有的 pandas 測試和程式碼,以使用新的引數
請參閱 測試警告 以了解更多資訊。
類型提示#
pandas 強烈建議使用 PEP 484 風格類型提示。新的開發應包含類型提示,且接受拉取請求以註解現有程式碼!
風格指南#
類型匯入應遵循 from typing import ... 慣例。您的程式碼可能會自動改寫為使用一些現代建構(例如,使用內建 list 代替 typing.List)由 提交前檢查。
在某些情況下,程式碼庫類別可能會定義遮蔽內建函式的類別變數。這會造成問題,如 Mypy 1775 中所述。此處的防禦性解決方案是建立內建函式的明確別名,並在沒有註解的情況下使用該別名。例如,如果您遇到類似這樣的定義
class SomeClass1:
str = None
註解此項目的適當方式如下
str_type = str
class SomeClass2:
str: str_type = None
在某些情況下,當您比分析器更了解時,您可能會想從 typing 模組使用 cast。這特別發生在使用自訂推論函式時。例如
from typing import cast
from pandas.core.dtypes.common import is_number
def cannot_infer_bad(obj: Union[str, int, float]):
if is_number(obj):
...
else: # Reasonably only str objects would reach this but...
obj = cast(str, obj) # Mypy complains without this!
return obj.upper()
這裡的限制在於,儘管人類可以合理地理解 is_number 會擷取 int 和 float 類型,但 mypy 目前還無法做出相同的推論(請參閱 mypy #5206)。儘管上述方法可行,但強烈不建議使用 cast。在適用的情況下,建議重構程式碼以安撫靜態分析
def cannot_infer_good(obj: Union[str, int, float]):
if isinstance(obj, str):
return obj.upper()
else:
...
對於自訂類型和推論,這並不總是可行,因此會產生例外,但在採用此類途徑之前,應盡一切努力避免 cast。
pandas 特定類型#
特定於 pandas 的常用類型會出現在 pandas._typing 中,您應在適用的情況下使用這些類型。此模組目前為私有,但最終應公開給想要針對 pandas 實作類型檢查的第三方程式庫。
例如,pandas 中的許多函式都接受 dtype 參數。這可以表示為字串,例如 "object",numpy.dtype,例如 np.int64,甚至可以表示為 pandas ExtensionDtype,例如 pd.CategoricalDtype。與其讓使用者必須不斷註解所有這些選項,不如從 pandas._typing 模組匯入並重複使用這些選項
from pandas._typing import Dtype
def as_type(dtype: Dtype) -> ...:
...
此模組最終將容納重複使用概念(例如「類別路徑」、「類別陣列」、「數值」等)的類型,並且還可以容納常用參數(例如 axis)的別名。此模組的開發很活躍,因此請務必參閱原始碼以取得最新可用的類型清單。
驗證類型提示#
pandas 使用 mypy 和 pyright 靜態分析程式碼庫和類型提示。在進行任何變更後,您可以透過在 Python 環境中執行以下指令,來確保您的類型提示是一致的:
pre-commit run --hook-stage manual --all-files mypy
pre-commit run --hook-stage manual --all-files pyright
pre-commit run --hook-stage manual --all-files pyright_reportGeneralTypeIssues
# the following might fail if the installed pandas version does not correspond to your local git version
pre-commit run --hook-stage manual --all-files stubtest
警告
請注意,以上指令將使用目前的 Python 環境。如果您的 Python 套件比 pandas CI 安裝的套件舊/新,以上指令可能會失敗。當
mypy或numpy版本不匹配時,通常會發生這種情況。請參閱 如何設定 Python 環境 或選擇 最近成功的流程,選擇「文件字串驗證、輸入和其它手動提交前掛勾」工作,然後按一下「設定 Conda」和「環境資訊」以查看 pandas CI 安裝的版本。
使用 pandas 測試程式碼中的類型提示#
警告
Pandas 尚未成為 py.typed 函式庫 (PEP 561)!在本地宣告 pandas 為 py.typed 函式庫的主要目的是測試和改善 pandas 內建的類型註解。
在 pandas 成為 py.typed 函式庫之前,可以透過在 pandas 安裝資料夾中建立一個名為「py.typed」的空檔,輕鬆地嘗試 pandas 附帶的類型註解。
python -c "import pandas; import pathlib; (pathlib.Path(pandas.__path__[0]) / 'py.typed').touch()"
py.typed 檔案的存在會向類型檢查器發出訊號,表示 pandas 已經是 py.typed 函式庫。這會讓類型檢查器知道 pandas 附帶的類型註解。
使用持續整合進行測試#
一旦提交拉取請求,pandas 測試套件將自動在 GitHub Actions 持續整合服務上執行。不過,如果您希望在提交拉取請求之前在分支上執行測試套件,則需要將持續整合服務連結到您的 GitHub 儲存庫。以下是 GitHub Actions 的說明。
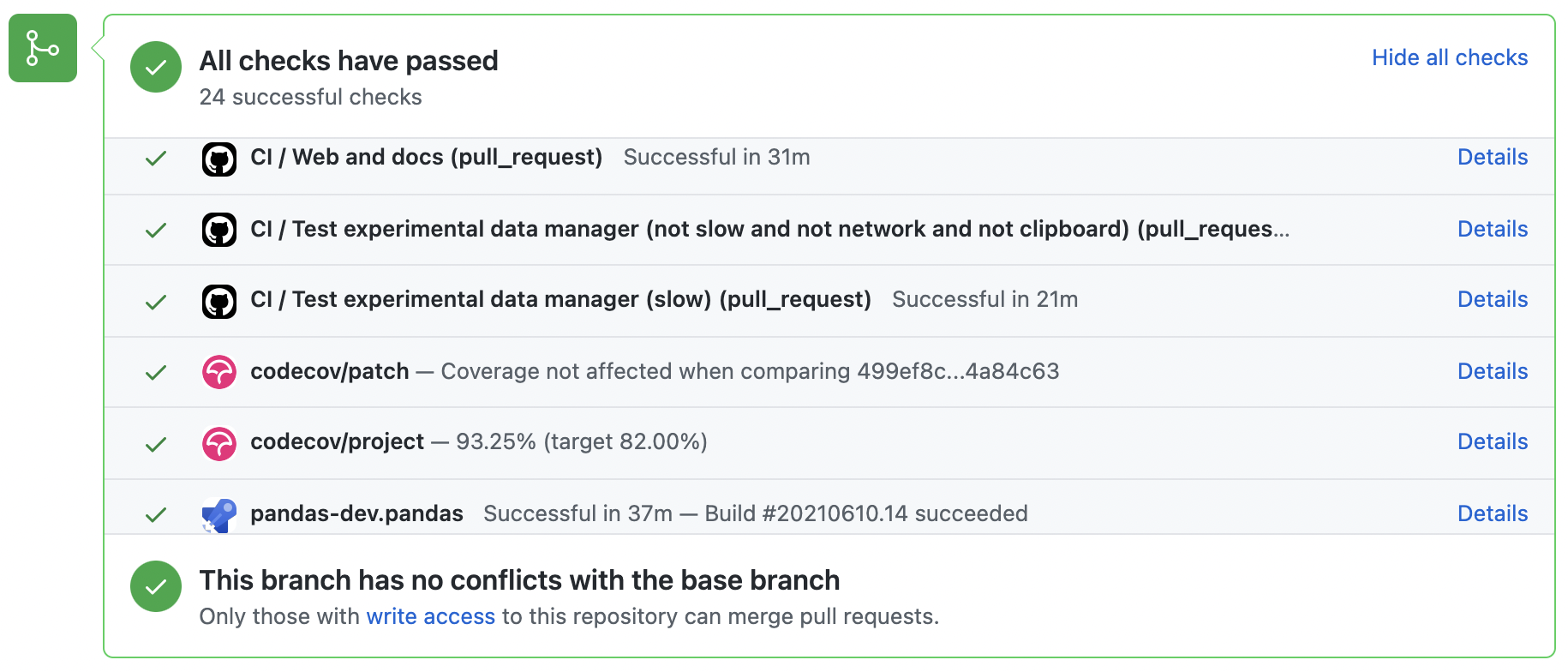
當所有建置都為「綠色」時,將考慮合併拉取請求。如果任何測試失敗,您將會看到一個紅色的「X」,您可以按一下以查看個別失敗的測試。以下是一個綠色建置的範例。
測試驅動開發#
pandas 非常重視測試,並強烈建議貢獻者採用 測試驅動開發 (TDD)。此開發流程「依賴於重複一個非常短的開發週期:首先,開發人員撰寫一個(最初會失敗的)自動化測試案例,定義所需的改善或新功能,然後產生通過該測試的最小程式碼量。」因此,在實際撰寫任何程式碼之前,您應該撰寫測試。測試通常可以從原始的 GitHub 問題中取得。不過,值得考慮其他使用案例並撰寫對應的測試。
在將程式碼推送到 pandas 之後,新增測試是最常見的要求之一。因此,養成事先撰寫測試的習慣是值得的,這樣就不會出現問題。
撰寫測試#
所有測試都應該放入特定套件的 tests 子目錄。這個資料夾包含許多目前的測試範例,我們建議參考這些範例以獲得靈感。
作為一個一般性的提示,你可以使用整合開發環境 (IDE) 中的搜尋功能或終端機中的 git grep 指令,來尋找呼叫方法的測試檔案。如果你不確定將測試放在哪個位置最好,請盡量猜測,但請注意審閱者可能會要求你將測試移至其他位置。
若要使用 git grep,你可以於終端機中執行下列指令
git grep "function_name("
這將搜尋儲存庫中所有檔案的文字 function_name(。這是一個快速找到程式碼庫中函數,並決定為其新增測試的最佳位置的有用方法。
理想情況下,應該只有一個明顯的位置可以放置測試。在我們達到這個理想之前,以下是一些關於測試放置位置的經驗法則。
你的測試是否僅依賴
pd._libs.tslibs中的程式碼?這個測試可能屬於下列其中之一tests.tslibs
注意
tests.tslibs中的檔案不應從pd._libs.tslibs以外的任何 pandas 模組匯入tests.scalar
tests.tseries.offsets
您的測試是否僅依賴 pd._libs 中的程式碼?此測試可能屬於下列其中之一:
tests.libs
tests.groupby.test_libgroupby
您的測試是否針對算術或比較方法?此測試可能屬於下列其中之一:
tests.arithmetic
注意
這些測試旨在透過
box_with_array固定裝置,來測試 DataFrame/Series/Index/ExtensionArray 的行為。tests.frame.test_arithmetic
tests.series.test_arithmetic
您的測試是否針對簡約方法(最小值、最大值、總和、乘積…)?此測試可能屬於下列其中之一:
tests.reductions
注意
這些測試旨在測試 DataFrame/Series/Index/ExtensionArray 的行為。
tests.frame.test_reductions
tests.series.test_reductions
tests.test_nanops
您的測試是否針對索引方法?這是決定測試歸屬的最困難案例,因為有許多此類測試,而且許多測試會測試多種方法(例如
Series.__getitem__和Series.loc.__getitem__)此測試是否特別測試 Index 方法(例如
Index.get_loc、Index.get_indexer)?此測試可能屬於下列其中之一:tests.indexes.test_indexing
tests.indexes.fooindex.test_indexing
在該檔案中應該有一個特定於方法的測試類別,例如
TestGetLoc。在大部分情況下,這些測試中不應需要
Series或DataFrame物件。測試是否為 Series 或 DataFrame 索引方法而非
__getitem__或__setitem__,例如xs、where、take、mask、lookup或insert?此測試可能屬於下列其中之一:tests.frame.indexing.test_methodname
tests.series.indexing.test_methodname
測試是否為
loc、iloc、at或iat?此測試可能屬於下列其中之一:tests.indexing.test_loc
tests.indexing.test_iloc
tests.indexing.test_at
tests.indexing.test_iat
在適當的文件中,測試類別對應於索引器類型(例如
TestLocBooleanMask)或主要使用案例(例如TestLocSetitemWithExpansion)。請參閱區段 D) 中關於測試多個索引方法的測試的說明。
測試是針對
Series.__getitem__、Series.__setitem__、DataFrame.__getitem__還是DataFrame.__setitem__?此測試可能屬於下列其中之一:tests.series.test_getitem
tests.series.test_setitem
tests.frame.test_getitem
tests.frame.test_setitem
如果許多案例,例如測試可能會測試多個類似的方法,例如:
import pandas as pd import pandas._testing as tm def test_getitem_listlike_of_ints(): ser = pd.Series(range(5)) result = ser[[3, 4]] expected = pd.Series([2, 3]) tm.assert_series_equal(result, expected) result = ser.loc[[3, 4]] tm.assert_series_equal(result, expected)
在這種情況下,測試位置應根據所測試的基礎方法。或者在測試錯誤修正的情況下,則是實際錯誤的位置。因此,在此範例中,我們知道
Series.__getitem__會呼叫Series.loc.__getitem__,因此這實際上是loc.__getitem__的測試。因此,此測試屬於tests.indexing.test_loc。您的測試是針對 DataFrame 還是 Series 方法?
此方法是繪圖方法嗎?此測試可能屬於下列其中之一:
tests.plotting
此方法是 IO 方法嗎?此測試可能屬於下列其中之一:
tests.io
注意
這包括
to_string,但不包括__repr__,後者在tests.frame.test_repr和tests.series.test_repr中進行測試。其他類別通常有test_formats檔案。
否則此測試可能屬於下列其中之一:
tests.series.methods.test_mymethod
tests.frame.methods.test_mymethod
注意
如果測試可以使用
frame_or_series固定裝置在 DataFrame/Series 之間共用,根據慣例,它會放在tests.frame檔案中。
你的測試是針對 Index 方法,不依賴於 Series/DataFrame 嗎?此測試可能屬於下列其中之一
tests.indexes
你的測試是針對由 pandas 提供的 ExtensionArrays 之一 (
Categorical、DatetimeArray、TimedeltaArray、PeriodArray、IntervalArray、NumpyExtensionArray、FloatArray、BoolArray、StringArray) 嗎?此測試可能屬於下列其中之一tests.arrays
你的測試是針對所有 ExtensionArray 子類別(「EA 介面」)嗎?此測試可能屬於下列其中之一
tests.extension
使用 pytest#
測試結構#
pandas 現有的測試結構大多數是基於類別的,表示你通常會在類別中找到已包裝的測試。
class TestReallyCoolFeature:
def test_cool_feature_aspect(self):
pass
我們偏好使用 pytest 架構的更具功能性的樣式,它提供更豐富的測試架構,有助於測試和開發。因此,我們不會撰寫測試類別,而是會撰寫像這樣的測試函式
def test_really_cool_feature():
pass
偏好的 pytest 慣用語#
名為
def test_*的函式測試,只接受固定裝置或參數作為引數。使用一個空的
assert來測試純量和真值測試使用
tm.assert_series_equal(result, expected)和tm.assert_frame_equal(result, expected)分別比較Series和DataFrame結果。在測試多個案例時,使用 @pytest.mark.parameterize。
在預期測試案例會失敗時,使用 pytest.mark.xfail。
在預期測試案例永遠不會通過時,使用 pytest.mark.skip。
在測試案例需要特定標記時,使用 pytest.param。
如果多個測試可以共用一個設定物件,請使用 @pytest.fixture。
警告
不要使用 pytest.xfail(它與 pytest.mark.xfail 不同),因為它會立即停止測試,而不會檢查測試是否會失敗。如果這是您想要的行為,請改用 pytest.skip。
如果已知測試會失敗,但失敗的方式並非預期要捕捉的,請使用 pytest.mark.xfail。通常會將此方法用於展示錯誤行為或未實作功能的測試。如果失敗的測試具有不穩定的行為,請使用參數 strict=False。這樣一來,如果測試碰巧通過,pytest 就不會失敗。強烈建議不要使用 strict=False,請僅將其視為最後的手段。
建議優先使用裝飾器 @pytest.mark.xfail 和參數 pytest.param,而非在測試中使用,以便在 pytest 的收集階段適當地標記測試。對於涉及多個參數、固定裝置或這些組合的失敗測試,只能在測試階段進行 xfail。若要執行此操作,請使用 request 固定裝置
def test_xfail(request):
mark = pytest.mark.xfail(raises=TypeError, reason="Indicate why here")
request.applymarker(mark)
xfail 不得用於涉及因無效使用者參數而失敗的測試。對於這些測試,我們需要驗證是否引發正確的例外類型和錯誤訊息,請改用 pytest.raises。
測試警告#
使用 tm.assert_produces_warning 作為內容管理員,以檢查程式碼區塊是否引發警告。
with tm.assert_produces_warning(DeprecationWarning):
pd.deprecated_function()
如果警告不應特別出現在程式碼區塊中,請將 False 傳遞到 context manager 中。
with tm.assert_produces_warning(False):
pd.no_warning_function()
如果您有會發出警告的測試,但您實際上並未測試警告本身(例如,因為它將在未來移除,或因為我們正在比對第三方程式庫的行為),請使用 pytest.mark.filterwarnings 忽略錯誤。
@pytest.mark.filterwarnings("ignore:msg:category")
def test_thing(self):
pass
測試例外#
使用 pytest.raises 作為 context manager,並帶有特定的例外子類別(即永遠不要使用 Exception)和 match 中的例外訊息。
with pytest.raises(ValueError, match="an error"):
raise ValueError("an error")
涉及檔案的測試#
tm.ensure_clean context manager 會建立一個暫存檔用於測試,並帶有產生的檔名(或您提供的檔名),當 context 區塊結束時會自動刪除。
with tm.ensure_clean('my_file_path') as path:
# do something with the path
涉及網路連線的測試#
單元測試不應存取網路上的公開資料集,因為網路連線不穩定,而且無法擁有要連線的伺服器。如要模擬此互動,請使用 pytest-localserver 外掛程式 中的 httpserver 固定裝置,並搭配合成資料。
@pytest.mark.network
@pytest.mark.single_cpu
def test_network(httpserver):
httpserver.serve_content(content="content")
result = pd.read_html(httpserver.url)
範例#
以下是在檔案 pandas/tests/test_cool_feature.py 中一個獨立的測試集範例,說明我們喜歡使用的多項功能。請記得將 GitHub Issue 號碼新增為新測試的註解。
import pytest
import numpy as np
import pandas as pd
@pytest.mark.parametrize('dtype', ['int8', 'int16', 'int32', 'int64'])
def test_dtypes(dtype):
assert str(np.dtype(dtype)) == dtype
@pytest.mark.parametrize(
'dtype', ['float32', pytest.param('int16', marks=pytest.mark.skip),
pytest.param('int32', marks=pytest.mark.xfail(
reason='to show how it works'))])
def test_mark(dtype):
assert str(np.dtype(dtype)) == 'float32'
@pytest.fixture
def series():
return pd.Series([1, 2, 3])
@pytest.fixture(params=['int8', 'int16', 'int32', 'int64'])
def dtype(request):
return request.param
def test_series(series, dtype):
# GH <issue_number>
result = series.astype(dtype)
assert result.dtype == dtype
expected = pd.Series([1, 2, 3], dtype=dtype)
tm.assert_series_equal(result, expected)
執行此測試會產生
((pandas) bash-3.2$ pytest test_cool_feature.py -v
=========================== test session starts ===========================
platform darwin -- Python 3.6.2, pytest-3.6.0, py-1.4.31, pluggy-0.4.0
collected 11 items
tester.py::test_dtypes[int8] PASSED
tester.py::test_dtypes[int16] PASSED
tester.py::test_dtypes[int32] PASSED
tester.py::test_dtypes[int64] PASSED
tester.py::test_mark[float32] PASSED
tester.py::test_mark[int16] SKIPPED
tester.py::test_mark[int32] xfail
tester.py::test_series[int8] PASSED
tester.py::test_series[int16] PASSED
tester.py::test_series[int32] PASSED
tester.py::test_series[int64] PASSED
我們已 參數化 的測試現在可透過測試名稱存取,例如我們可以使用 -k int8 來子選取僅符合 int8 的測試。
((pandas) bash-3.2$ pytest test_cool_feature.py -v -k int8
=========================== test session starts ===========================
platform darwin -- Python 3.6.2, pytest-3.6.0, py-1.4.31, pluggy-0.4.0
collected 11 items
test_cool_feature.py::test_dtypes[int8] PASSED
test_cool_feature.py::test_series[int8] PASSED
使用 hypothesis#
Hypothesis 是用於基於屬性的測試的函式庫。您不必明確參數化測試,而是可以描述所有有效輸入,並讓 Hypothesis 嘗試找出失敗的輸入。更棒的是,不論 Hypothesis 嘗試了多少個隨機範例,它總是會回報一個最小的反例來反駁您的斷言,通常是您從未想過要測試的範例。
請參閱 開始使用 Hypothesis 以取得更多簡介,然後 參閱 Hypothesis 文件以取得詳細資訊。
import json
from hypothesis import given, strategies as st
any_json_value = st.deferred(lambda: st.one_of(
st.none(), st.booleans(), st.floats(allow_nan=False), st.text(),
st.lists(any_json_value), st.dictionaries(st.text(), any_json_value)
))
@given(value=any_json_value)
def test_json_roundtrip(value):
result = json.loads(json.dumps(value))
assert value == result
此測試展示了 Hypothesis 的幾個有用功能,並展示了一個良好的使用案例:檢查應在大量或複雜的輸入網域中保留的屬性。
為讓 pandas 測試套件快速執行,如果輸入或邏輯很簡單,則建議使用參數化測試,而 Hypothesis 測試則保留給邏輯複雜的情況,或選項組合太多或互動微妙,無法測試(或想到!)所有這些情況。
執行測試套件#
然後,輸入以下內容,即可直接在 Git 分身中執行測試(無需安裝 pandas):
pytest pandas
注意
如果少數測試未通過,這可能不是你的 pandas 安裝問題。有些測試(例如一些 SQLAlchemy 測試)需要額外設定,其他測試可能會開始失敗,因為未固定的程式庫發布了新版本,而其他測試如果並行執行可能會不穩定。只要你可以從本地建置版本匯入 pandas,你的安裝可能就沒問題,你可以開始貢獻了!
通常,在執行整個套件之前,先針對你的變更執行測試子集是值得的(提示:你可以使用 pandas-coverage 應用程式)找出哪些測試會影響你修改的程式碼行,然後只執行這些測試)。
執行此操作最簡單的方法是
pytest pandas/path/to/test.py -k regex_matching_test_name
或使用以下其中一種建構
pytest pandas/tests/[test-module].py
pytest pandas/tests/[test-module].py::[TestClass]
pytest pandas/tests/[test-module].py::[TestClass]::[test_method]
使用 pytest-xdist,它包含在我們的「pandas-dev」環境中,可以在多核心機器上加速本地測試。然後,在執行 pytest 以在指定核心數上並行化測試執行或自動使用機器上所有可用核心時,可以指定 -n 數字旗標。
# Utilize 4 cores
pytest -n 4 pandas
# Utilizes all available cores
pytest -n auto pandas
如果你想進一步加快速度,這個指令的更進階用法如下所示
pytest pandas -n 4 -m "not slow and not network and not db and not single_cpu" -r sxX
除了多執行緒效能提升外,這也透過使用 -m 標記旗標跳過某些測試來提升測試速度
slow:任何執行時間長的測試(以秒為單位,而非毫秒)
network:需要網路連線的測試
db:需要資料庫(mysql 或 postgres)的測試
single_cpu:應該只在單一 CPU 上執行的測試
如果與你相關,你可能想要啟用下列選項
arm_slow:任何在 arm64 架構上執行時間長的測試
這些標記定義在 這個 toml 檔案 中,在 [tool.pytest.ini_options] 下的 markers 清單中,如果你想要檢查是否有任何新的標記已建立且與你相關。
-r 報告旗標會顯示一個簡短的摘要資訊(請參閱 pytest 文件)。在此我們顯示下列數目
s:已跳過的測試
x:xfailed 測試
X:xpassed 測試
摘要是選用的,如果你不需要額外的資訊,可以移除。使用平行化選項可以在提交拉取請求前顯著減少在本地執行測試所需的時間。
如果你需要協助處理結果(過去曾發生過),請在執行指令和開啟錯誤報告前設定種子,這樣我們才能重製它。以下是在 Windows 上設定種子的範例
set PYTHONHASHSEED=314159265
pytest pandas -n 4 -m "not slow and not network and not db and not single_cpu" -r sxX
在 Unix 上使用
export PYTHONHASHSEED=314159265
pytest pandas -n 4 -m "not slow and not network and not db and not single_cpu" -r sxX
更多資訊,請參閱 pytest 文件。
此外,可以執行
pd.test()
使用已匯入的 pandas 來以類似的方式執行測試。
執行效能測試套件#
效能很重要,值得考慮您的程式碼是否引入了效能退化。pandas 正在將 asv benchmarks 遷移至,以輕鬆監控關鍵 pandas 作業的效能。這些基準測試都可以在 pandas/asv_bench 目錄中找到,而測試結果可以在 這裡 找到。
若要使用 asv 的所有功能,您需要 conda 或 virtualenv。有關更多詳細資訊,請查看 asv 安裝網頁。
若要安裝 asv
pip install git+https://github.com/airspeed-velocity/asv
如果您需要執行基準測試,請將您的目錄變更為 asv_bench/ 並執行
asv continuous -f 1.1 upstream/main HEAD
您可以將 HEAD 替換為您正在處理的分支名稱,並報告變動超過 10% 的基準測試。此命令預設使用 conda 來建立基準測試環境。如果您想要改用 virtualenv,請撰寫
asv continuous -f 1.1 -E virtualenv upstream/main HEAD
應將 -E virtualenv 選項新增至所有執行基準測試的 asv 命令。預設值定義在 asv.conf.json 中。
執行完整基準測試套件可能是一整天的事,視你的硬體和資源使用情況而定。然而,通常只要將結果的子集貼到拉取要求中,就能證明提交的變更不會導致意外的效能退化。你可以使用 -b 旗標執行特定基準測試,它會採用正規表示法。例如,這只會執行 pandas/asv_bench/benchmarks/groupby.py 檔案中的基準測試
asv continuous -f 1.1 upstream/main HEAD -b ^groupby
如果你只想執行檔案中特定群組的基準測試,你可以使用 . 作為分隔符號。例如
asv continuous -f 1.1 upstream/main HEAD -b groupby.GroupByMethods
只會執行 groupby.py 中定義的 GroupByMethods 基準測試。
你也可以使用目前 Python 環境中已安裝的 pandas 版本執行基準測試套件。如果你沒有 virtualenv 或 conda,或者正在使用上面討論的 setup.py develop 方法,這會很有用;對於就地建置,你需要設定 PYTHONPATH,例如 PYTHONPATH="$PWD/.." asv [remaining arguments]。你可以透過以下方式使用現有的 Python 環境執行基準測試
asv run -e -E existing
或者,使用特定的 Python 解譯器
asv run -e -E existing:python3.6
這會顯示基準測試的 stderr,並使用來自 $PATH 的本機 python。
有關如何撰寫基準測試以及如何使用 asv 的資訊,請參閱 asv 文件。
記錄您的程式碼#
變更應反映在位於 doc/source/whatsnew/vx.y.z.rst 中的發行說明中。此檔案包含每個版本的持續變更記錄。新增一個項目至這個檔案,以記錄您的修正、加強功能或(不可避免的)重大變更。在新增項目時,請務必包含 GitHub 問題編號(使用 :issue:`1234`,其中 1234 是問題/合併請求編號)。您的項目應使用完整的句子和適當的文法撰寫。
在提到 API 的部分時,請適當地使用 Sphinx :func:、:meth: 或 :class: 指令。並非所有公開的 API 函式和方法都有文件頁面;理想情況下,僅在它們解析時才新增連結。您通常可以透過查看先前版本之一的發行說明來找到類似的範例。
如果您的程式碼是修正錯誤,請將您的項目新增至相關的修正錯誤區段。避免新增至 其他 區段;只有在少數情況下,項目才應新增至該區段。錯誤說明應盡可能簡潔,包括使用者可能如何遭遇此錯誤以及錯誤本身的指示,例如「產生不正確的結果」或「不正確地引發」。可能需要同時指示新的行為。
如果您的程式碼是增強功能,很可能需要將使用範例新增至現有文件。這可以依照關於 文件 的章節進行。此外,為了讓使用者知道此功能何時新增,會使用 versionadded 指令。Sphinx 的語法如下
.. versionadded:: 2.1.0
這會將文字 2.1.0 版的新功能 放在您放置 Sphinx 指令的任何位置。在新增函式或方法 (範例) 或新的關鍵字參數 (範例) 時,也應該將此文字放入文件字串中。